Introduction
If you have been reading this book alongside working through the web program, by now you will have decided on your research method and your research question(s) and/or hypothesis. Now it is time to start to plan your research in detail and one of the first things that you will need to sort out is the sample for your research study.
This chapter, and the sample section in the web program, discuss what a sample is and how you can obtain the most appropriate one for your research.
What is a sample?
As you learned in chapter 5, a sample is a group of people who have been selected to act as representatives of a population as a whole. A population in terms of a research study consists of the people who may be affected by the phenomenon that you are investigating (e.g. people with HIV and drug dependency in the UK). The sample that you choose has to be large enough to allow you to investigate fully the phenomenon that is of interest to you using the research methodology that you think will best answer the research question/problem or prove/disprove your hypothesis.
According to Neutens & Rubinson (2002: 140): ‘A knowledgeable researcher commences with a population and works down to a sample.’ In other words, you select the population you wish to study and then derive your sample from that population rather than obtain your sample and then decide what the population will be. If you work out your sample first, you may find that it is not representative of the population that you are interested in (e.g. recruiting a sample of university undergraduates and then looking at the incidence and treatment of bipolar disorder or obesity among them and extrapolating your findings to the total UK population). So, it is important to determine your population and then settle on your sample, which should be as representative of that population as possible.
Why use a sample?
The simple answer is that it saves you time and money. For example, if you are interested in looking at an aspect of patients with diabetes mellitus living in the UK, you would find it almost impossible to study this with any accuracy in such a large number of people. It would be very expensive to contact everyone with diabetes mellitus in the UK and extremely time-consuming (Polit & Hungler 1999).
However, there are other reasons for using a sample than time and money alone. The possibility of achieving a much better response rate from a sample as opposed to a response rate from a population is greatly increased by limiting it to fewer people. The advantage of a good response rate is that it tends to make the results more accurate and valid, assuming your sample is truly representative of the population.
Certainly, in qualitative research where, for example, you may wish to do one-to-one interviewing, using a sample makes such research possible. This would not be the case if you were to attempt to interview a whole population. Whilst interviewing a whole population is feasible, you would need to recruit many interviewers, and this would certainly increase the costs and at the same time increase the problem of standardising the interviews.
We have mentioned above the importance of the representativeness of your sample. This is particularly important when considering quantitative research. So what do we mean by sample representativeness? According to Telhaj et al. (2004: 1), ‘representativeness expresses the degree to which sample data accurately and precisely represents a characteristic of a population’s parameter variations at a sampling point.’ In simple terms, by representativeness we mean that we want the sample to have all the qualities and aspects of our population, and that means that the sample must include the same differences as are found in the population as a whole. For example, if we wish to investigate the effects on health of instituting a regime of a set type and amount of exercise with the elderly in Lancashire, we would need to look at the whole population of Lancashire and then look at the variation within the elderly population of Lancashire – age range, ethnic/racial percentages and gender populations. We would then try to ensure that our sample includes the same variations in the same proportions.
One of the main purposes of sample representativeness is to eliminate bias – hence its importance in quantitative research because it is essential in such research that bias is eliminated, whereas in qualitative research, where representativeness is not always the goal, any bias is acknowledged and is not so much a concern. Such biases can arise, for example, from a sample which does not truly represent the participant population (Telhaj et al. 2004).
There are other forms of bias, such as researcher or interviewer bias, but these are not concerned with the sample and are discussed in chapters 4, 5 and 8 and in the web program.
In terms of preventing sample bias, Telhaj et al. (2004: 1) point out that ‘the representativeness criterion is best satisfied by making certain that sampling locations are selected properly and a sufficient number of samples are collected’. In effect, sampling bias occurs when there is either over- or under-representation of participants with the characteristic of interest to the researcher in the sample (Polit & Hungler 1999). For example, suppose you are interested in the quality of life of children with diabetes mellitus and you decide to undertake your research by taking a sample of children with this disease and asking them to fill in a questionnaire related to their quality of life. This is reasonable. But suppose you obtain your sample from children who frequently attend A&E because they have become ketoacidotic. This will bias your research because the sample is not representative of all children with diabetes mellitus, who are generally able to control their diabetes. (Of course, if you wanted to research the quality of life of children who attend hospital as an emergency because of ketoacidosis, then your sample would be fine.)
Probability and non-probability
Before we move on to look at different types of samples, a few points about two major classes of sampling methods that we use, namely probability sampling methods and non-probability sampling methods, are in order. Probability sampling is any method that produces samples that have been randomly selected. In order for your samples to be randomly selected, you need to have mechanisms in place that will ensure that the participants have the same chance (or possibility) of being selected. The simplest forms of random selection are picking a name out of a hat or drawing the ‘short straw’. These days, we are more likely to use a computer as the means for generating random numbers as the basis for random selection.
Non-probability sampling does not have a mechanism for random selection, and therefore not all members of a population will have an equal probability of being in the sample. For this reason, non-probability sampling methods are usually not recommended for a research study if you want to generalise from the sample to the population as a whole. Although non-probability sampling is much less expensive than probability sampling, the results are of limited value if the generalisation of results is required. However, in many qualitative research studies, where generalisation of results is not required, it is in order to use non-probability methods to obtain your sample.
Examples of non-probability sampling include:
- convenience, haphazard or accidental sampling (see below);
- snowball sampling (see below);
- purposive sampling (see below);
- deviant case sampling – obtaining cases that differ substantially from the dominant pattern (this is a special type of purposive sample);
- case study – the research is limited to a small group with a similar characteristic, or even to a single person;
- quota sampling – here you decide in advance on a quota (for example, 30% made up of people aged 21–40, 30% aged 41–60 and 40% aged 61 and over) and then are free to choose anyone as long as the quota is met.
So now you know that the difference between non-probability and probability sampling is that the former does not involve random selection whilst probability sampling does.
With probability sampling, we are able to estimate confidence intervals for statistics (see chapter 8). With non-probability samples, the population may not be represented – or only weakly represented – by the sample so we cannot do this. Generally, however, researchers, even qualitative researchers, prefer probability random over non-probability sampling methods, as they are considered to be more accurate and rigorous.
However, in certain types of research, particularly in applied social or nursing research, there may be circumstances where, for various reasons, it is not feasible, practical or theoretically possible to have random samples, in which case non-probability sampling techniques can be used and, as long as a good rationale is given, it is usually acceptable.
Finally, it is important to note that even studies that started with probability samples may end up with non-probability samples due to unintentional or unavoidable characteristics of the sampling method. However, ideally we shall use probability samples, so let us now have a closer look at the different types of probability samples.
Types of probability sample
Random samples
As the term suggests, with a random sample the people who make up the sample have been chosen at random. The aim of selecting a sample randomly is to eliminate the risk of bias, and the principle behind a random sample is that each member in the population should have a greater than zero opportunity of being selected.
This type of sample is more usually used in experimental quantitative research designs rather than in qualitative research, although it is sometimes used in qualitative research.
There are different types of probability/random sampling. These include:
- simple random sampling;
- stratified random sampling;
- cluster sampling;
- systematic sampling.
In these the attributes of the sample and the population are a function of chance.
Simple random sampling
This type of sampling is the most basic of the probability sampling methods. Before undertaking this we first need to determine a sampling frame. Basically, a sampling frame is a comprehensive list of the members of the population that, as researchers, we are interested in. For example, to investigate a particular aspect of people who are assessing the diabetes services in a given area (i.e. your population), you would need to know the names of all the people in that area who are accessing the diabetes service. From these names you can randomly select an appropriate number as representatives of the population (i.e. your sample) whom you can invite to take part in the research. If we do not have such a sampling frame, then we are restricted to less satisfactory forms of samples which cannot be randomly selected because not all individuals within that population will have the same probability of being selected (Blacktop 1996). We would then have a non- probability sample (see below and the web program).
Once you have a list of all the population elements (e.g. people), they are numbered consecutively. You then need to select a method of randomly selecting the people who will make up your sample. This could be something as basic as closing your eyes and sticking a pin anywhere on the list of names; that person is then invited to be included in your sample. Alternatively, you could use a sophisticated computer program, or any method between the two. Consequently, a sample selected randomly in this way cannot be subject to researcher bias. Polit & Hungler (1999: 285) make the point that ‘although there is no guarantee that a randomly drawn sample will be representative, random selection does ensure that differences in the attributes of the sample and the population are purely a function of chance’.
Stratified random sampling
This is a variant of simple random sampling, but in this type of sampling, before the sample is selected, the population is divided into two (or more) subgroups (or strata). The purpose of stratified sampling is to improve the representativeness of the sample. Put simply, stratified sampling is the process of subdividing the population into homogeneous subsets (i.e. each of the two subsets contain people who share the same characteristics, but there are differences between the people in the two subsets). From these two (or more) homogeneous subsets, the appropriate number from the population can be selected at random. These subsets/strata can be based on any number of attributes (e.g. age, gender, disease, medication) (Polit & Hungler 1999). One point to bear in mind is that your subsets may be unequal in size; in this case, you may wish to select your sample in numbers proportionate to the subgroups in your population. This is similar to quota sampling, a form of non-probability sample, and is composed of prespecified numbers of participants, who are included because they have similar percentages of specific characteristics of interest to the researcher as the target population.
Cluster sampling
Cluster sampling comes into its own when your population is very large (e.g. the whole country) and it is physically and/or financially not feasible to undertake your research on a sample drawn from all over the country. If this is the case, you may wish to select certain areas of the country at random (sticking a pin in a map whilst blindfolded is as good as a way as any of doing this) and then randomly select your sample from those areas only.
Whilst cluster sampling is far easier and cheaper than simple random sampling when you are dealing with a very large and dispersed population, there is, as Blacktop (1996) points out, a price to pay in terms of precision. If we intend to use cluster sampling in our research, we have to take into account that, as Blacktop (1996: 11) says, ‘our political and social attitudes are shaped by the people we live and work with. Because of this, the people within a cluster tend to be similar to each other and to be different from people in other clusters.’
In cluster sampling, Polit & Hungler (1999) explain that there is a successive random sampling of units within the population, commencing with sampling large groupings (clusters), then sampling subunits within the larger groupings, followed by sampling smaller subunits within these, and so on. Because there is successive sampling of ever smaller units, this approach is often referred to as multistage sampling. It is important to note that the cluster samples can be selected by simple or stratified sampling methods.
Polit & Hungler (1999) note that there is a risk that cluster sampling will contain more sampling errors than either simple or stratified random sampling. Despite this, the method remains less expensive and is more practical than other types of probability sampling when your population is large and widely dispersed.
Systemic sampling
Systemic sampling involves the selection, not so much randomly as selectively, of every second, fifth or tenth (or whatever ordinal number you wish to use) person on a list. There is a formula for determining your sampling interval (Polit & Hungler 1999), and this is:
Sampling interval = population number divided by required sample number.
If, for example, you have a population of 1,000 and you want a sample of 100, then your equation is:
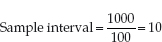
So you would select every tenth person on your population list. You then have to randomly select a starting point (again, sticking a pin in the list method is as good as any), so your starting point might be 12. In this case, you would select numbers 12, 22, 32, 42, and so on until you have reached the end, and then you would start at the beginning, so in this case your 100th participant would be number 2 because you have returned to the beginning of the list.
This sampling design can be thought of as either probability sampling or non-probability sampling; it depends on whether you select your sample randomly as above, or start your sample interval at number 1.
Types of non-probability sample
We now turn to non-probability sampling.
As a brief introduction to the different types of non-probability samples, here are some of the most common types.
Theoretical sampling
‘Theoretical sampling is the process of data collection for generating theory whereby the researcher jointly collates, codes and analyses data and decides what data to collect and who to collect it from, in order to develop his/her theory as it emerges’ (Ingleton 2004).
Theoretical sampling is the term used by Glaser & Strauss (1967) to describe the manner in which sources of data can be identified and then selected for inclusion in a grounded theory study (Benton 2000). The goal of theoretical sampling is completely different from probabilistic sampling (discussed above). Here, your goals as a researcher are to gain a deeper understanding of the analysed cases and from them begin to develop the analytical framework and concepts that you will use in your research.
In theoretical sampling participants are selected because it is felt that they can inform the researcher’s developing understanding of the area of investigation. It is often used in grounded theory research in order to develop a theory through the research process itself. The idea is that the researcher collects data from any individual, or any group of people, who can provide the appropriate and relevant data for the generation of the theory.
In theoretical sampling, unlike other sampling methods, it is impossible to identify the size and characteristic of the sample at the beginning of the study as the sample size and characteristics grow as you generate more data until you have exhausted the source of new data (you have reached theoretical saturation), so, in effect, you can only identify your sample retrospectively once you have generated your theory.
Purposive sample
Purposive sampling (also known as judgemental sampling) is a non-probability technique that involves the selection of certain people whom the researcher wishes to include in the study. Participants are selected because they have certain characteristics that are of interest – for example, they have had the experience in which the researchers are interested or there are aspects of their lives which the researcher wishes to explore. In other words, the researcher deliberately (or purposely – hence the name) selects participants who, they believe, can add to the developing theory, support it or even refute the theory that is being developed to investigate the topic that is of interest, and hence is being researched (Ingleton 2004).
Convenience (haphazard or accidental) sampling
Convenience sampling (also known as accidental sampling) is a type of non-probability sampling in which people are included in the research study because they happen to be in the right place at the right time (Burns & Grove 2005). Put simply from the point of view of the healthcare professional, a convenience sample is a group of participants to whom the researcher has access – for example, patients/clients on a ward or in a clinic or the community, or nurses/other healthcare professionals in a hospital.
However, convenience sampling is considered by many to be a weak approach (but not as weak as volunteer sampling – see below) because it risks the introduction of bias. Indeed, to stress this, Burns & Grove (2005) contest that multiple biases, ranging from minimal to serious biases, may be found in convenience samples. This, accordingly, puts great responsibility on the researcher to identify and then describe any known biases that may exist. Once these have been identified, steps need to be taken to improve the representativeness of the sample. Transparency in sample selection and data collection is important in all research, but the use of convenience sampling greatly adds to the need for this.
In terms of sample size, in accidental/convenience sampling, potential participants are simply entered into the study until the desired sample size is reached. Thus there is no selection as such taking place other than that the participants are conveniently to hand at the start of the study.
Snowball sampling
Snowball sampling (also known as network or nominated sampling) takes advantage of existing social networks and the fact that friends and colleagues tend to have characteristics in common (Burns & Groves 2005). In a snowball sample, participants who are already part of the sample (often because of convenience sampling) are asked to identify others who may be suitable for inclusion and are likely to agree to take part. In other words, the sample gradually increases in size, like a snowball rolling down a snow-covered hill. This type of sample is useful when the researcher is studying a sub-group who may not easily be accessible by other means (e.g. drug users).
Another advantage of snowball sampling is that it can be an effective strategy for the identification of participants who are able to provide important insights, knowledge, understanding and information about the experience or event that is the focus of the research.
Volunteer sampling
A volunteer sample is one in which the participants have volunteered to take part in the study. This type of sample is generally regarded as the weakest form of sampling, but it is useful when respondents are difficult to recruit by any other means (see also snowball sampling above).
A major problem with a volunteer sample is that the participants may have volunteered because they have their own agenda or ulterior motives, which may conflict with the researcher’s aims, so the risk of bias in the sample and within/between individuals is very high.
So much for how we decide which sample we are going to use in our research study. Remember that we choose a sample because it is often not possible to investigate a whole population. However, the number of participants that comprise the sample is very important for the reasons discussed at the beginning of this chapter. In the next section we turn to the sizes of samples and how we can ensure that we obtain the correct size.
The size of samples
Ingleton (2004: 123) poses the question ‘does sample size matter?’ She next ponders the question, if it does matter, how can we ensure that a sample is large enough for our purpose? She concludes that there are no simple rules we can apply that will inform us whether or not we have the correct size sample for our research.
There are certain types of research – mainly quantitative – where formulae are used to determine the sample size, and we shall discuss these later in this chapter. But whilst, ideally or theoretically, sample sizes may be determined with scientific principles in mind, in the real world sample sizes have to be achieved within the limitations that a researcher will encounter (Ingleton 2004).
Is this important? Burns & Grove (2005) believe that an inadequate sample size may well reduce both the quality and credibility of any findings from a research study. Similarly, in quantitative research, if your sample is too small, you may not be able to justify any generalisations to the whole population that you make from your findings.
The size of the sample depends largely on the aims and purpose of the research, as well as the current time and methodology used to undertake the research study (Merriam 1998). In terms of size, the main differences are between samples for quantitative research and samples for qualitative research. The major difference occurs because in qualitative research essentially we are concerned with the quality of the information that is being discovered, whilst in quantitative research the principal aim is often to identify relationships, causal or otherwise, between variables.
So we shall take these two paradigms as separate entities, commencing with samples for qualitative research.



