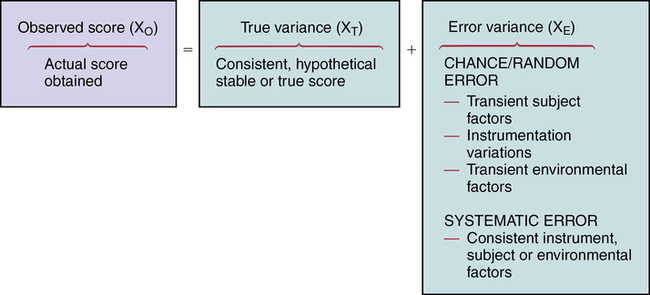
CHAPTER 15 Geri LoBiondo-Wood and Judith Haber After reading this chapter, you should be able to do the following: • Discuss how measurement error can affect the outcomes of a research study. • Discuss the purposes of reliability and validity. • Discuss the concepts of stability, equivalence, and homogeneity as they relate to reliability. • Compare and contrast the estimates of reliability. • Compare and contrast content, criterion-related, and construct validity. • Identify the criteria for critiquing the reliability and validity of measurement tools. • Use the critiquing criteria to evaluate the reliability and validity of measurement tools. • Discuss how evidence related to reliability and validity contributes to the strength and quality of evidence provided by the findings of a research study and applicability to practice. Go to Evolve at http://evolve.elsevier.com/LoBiondo/ for review questions, critiquing exercises, and additional research articles for practice in reviewing and critiquing. An observed test score that is derived from a set of items actually consists of the true score plus error (Figure 15-1). The error may be either chance error or random error, or it may be systematic or constant error. Validity is concerned with systematic error, whereas reliability is concerned with random error. Chance or random errors are errors that are difficult to control (e.g., a respondent’s anxiety level at the time of testing). Random errors are unsystematic in nature. Random errors are a result of a transient state in the subject, the context of the study, or the administration of an instrument. For example, perceptions or behaviors that occur at a specific point in time (e.g., anxiety) are known as a state or transient characteristic and are often beyond the awareness and control of the examiner. Another example of random error is in a study that measures blood pressure. Random error resulting in different blood pressure readings could occur by misplacement of the cuff, not waiting for a specific time period before taking the blood pressure, or placing the arm randomly in relationship to the heart while measuring blood pressure. The concept of error is important when appraising instruments in a study. The information regarding the instruments’ reliability and validity is found in the instrument or measures section of a study, which can be separately titled or appear as a subsection of the methods section of a research report, unless the study is a psychometric or instrument development study (see Chapter 10). As you read the instruments or measures sections of studies, you will notice that validity data are reported much less frequently than reliability data. DeVon and colleagues (2007) note that adequate validity is frequently claimed, but rarely is the method specified. This lack of reporting, largely due to publication space constraints, shows the importance of critiquing the quality of the instruments and the conclusions (see Chapters 14 and 17). When the researcher has completed this task, the items are submitted to a panel of judges considered to be experts about the concept. For example, researchers typically request that the judges indicate their agreement with the scope of the items and the extent to which the items reflect the concept under consideration. Box 15-1 provides an example of content validity. Another method used to establish content validity is the content validity index (CVI). The content validity index moves beyond the level of agreement of a panel of expert judges and calculates an index of interrater agreement or relevance. This calculation gives a researcher more confidence or evidence that the instrument truly reflects the concept or construct. When reading the instrument section of a research article, note that the authors will comment if a CVI was used to assess the content validity of an instrument. When reading a psychometric study that reports the development of an instrument, you will find great detail and a much longer section of how exactly the researchers calculated the CVI and the acceptable item cut-offs. In the scientific literature there has been discussion of accepting a CVI of .78 to 1.0 depending on the number of experts (DeVon et al., 2007; Lynn, 1986). An example from a study that used CVI is presented in Box 15-1. A subtype of content validity is face validity, which is a rudimentary type of validity that basically verifies that the instrument gives the appearance of measuring the concept. It is an intuitive type of validity in which colleagues or subjects are asked to read the instrument and evaluate the content in terms of whether it appears to reflect the concept the researcher intends to measure. Criterion-related validity indicates to what degree the subject’s performance on the instrument and the subject’s actual behavior are related. The criterion is usually the second measure, which assesses the same concept under study. For example, in a study by Sherman and colleagues (2012) investigating the effects of psychoeducation and telephone counseling on the adjustment of women with early-stage breast cancer, criterion-related validity was supported by correlating amount of distress experienced (ADE) scores measured by the Breast Cancer Treatment Response Inventory (BCTRI) and total scores from the Symptom Distress Scale (r = .86; p < .000). Two forms of criterion-related validity are concurrent and predictive. Predictive validity refers to the degree of correlation between the measure of the concept and some future measure of the same concept. Because of the passage of time, the correlation coefficients are likely to be lower for predictive validity studies. Examples of concurrent and predictive validity as they appear in research articles are illustrated in Box 15-2. Construct validity is based on the extent to which a test measures a theoretical construct, attribute, or trait. It attempts to validate the theory underlying the measurement by testing of the hypothesized relationships. Testing confirms or fails to confirm the relationships that are predicted between and/or among concepts and, as such, provides more or less support for the construct validity of the instruments measuring those concepts. The establishment of construct validity is complex, often involving several studies and approaches. The hypothesis-testing, factor analytical, convergent and divergent, and contrasted-groups approaches are discussed below. Box 15-3 provides examples of different types of construct validity as it is reported in published research articles.
Reliability and validity

Reliability, validity, and measurement error
Validity
Content validity
Criterion-related validity
Construct validity
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Reliability and validity
Get Clinical Tree app for offline access
