Technology, applications and security
Melissa Saul
Objectives
After reading this chapter, the reader will be able to do the following:
• Define and describe the overall scope of health information systems.
• Discuss the evolution of information technology in health care.
• Explain the fundamental concepts of database models.
• Understand the functionality of structured query language.
• Explain how a wireless network communicates with the devices on the network.
• Characterize the differences between two-tier and three-tier architectures.
• Identify network protocols used on the Internet.
• Apply interface design principles to screen and other input devices.
• Be familiar with standards for designing Web pages.
• Describe the role of an interface engine.
• Provide the advantages of computerized provider order entry systems.
• Define scenarios in which bar code technology could be used.
• Discuss the purpose and applications of telehealth.
• Explain the authentication tools used by information systems.
• Build a case for why a firewall is necessary.
• Understand the types of malicious software.
• Define the role of the secure socket layer in Internet applications.
• Explain various techniques used to address security of health information systems.
• Discuss the benefits of an application service provider model.
• Describe the steps for building a data mart.
• Understand how data collected in a health information system can be used for research.
Key words
Applets
Application gateway
Application software
ARDEN syntax
Ascension number
Authentication
Bandwidth
Biometric
Break Glass
Business rules
Cascading Style Sheets
Checksum
Clinical decision support systems
Data compression
Data mart
Data mining
Data repository
Database
Database management system
Database model
Decision support systems
Disaster Recovery
Encryption
Ethernet
Expert system
Extranet
Firewall
Frames
Granularity
Hardware
Hierarchical
Interface engine
Internet
Intranet
JAVA
Knowledge base
Lossless
Lossy
Mainframe
Malware
Medical informatics
Microcomputers
Middleware
Minicomputers
Network
Object
Object-oriented
Operating system
Order entry
Packet filter
Password aging
Phishing
Pointer
Point-of-care system
Point-to-point
Primary key
Protocols
Proxy server
Public key
Relational model
Results reporting
Servlet
Software
Store and forward
Symbology
Syndromic surveillance system
Tags
Templates
Terminals
Thick-client
Thin-client
Three-tier
Token ring
Two-factor authentication
Two-tier
Voice recognition
Wi-Fi
Wireless
Workstation
Abbreviations
ADT—Admission, Discharge, and Transfer
ANSI—American National Standards Institute
ASP—Application Service Provider
ASTM—American Society for Testing and Materials
ATM—Asynchronous Transfer Mode
CCOW—Clinical Context Object Workstation
CGI—Common Gateway Interface
COBOL—Common Business-Oriented Language
CODEC—Coder/Decoder
CPOE—Computerized Provider Order Entry
DOS—Denial of Service
DTD—Document Type Definition
DMZ—Demilitarized Zone
EIS—Executive Information Systems
ERP—Enterprise Resource Planning
FDDI—Fiber-Distributed Data Interface
HTML—Hypertext Markup Language
HTTP—Hypertext Transfer Protocol
IEEE—Institute of Electrical and Electronic Engineers
IETF—Internet Engineering Task Force
ISO—International Organization of Standardization
JVM—Java Virtual Machine
LAN—Local Area Network
MUMPS—Massachusetts General Hospital Utility Multi-Programming System
PDA—Personal Digital Assistant
RBAC—Role-Based Access Control
RFID—Radio Frequency Identification Device
SGML—Standardized Generalized Markup Language
S-HTTP—Secure Hypertext Transfer Protocol
SQL—Standard Query Language
SSL—Secure Socket Layer
TCP/IP—Transmission Control Protocol/Internet Protocol
VPN—Virtual Private Network
W3—World Wide Web Consortium
WAN—Wide Area Networks
WEP—Wired Equivalent Privacy
WPA—Wi-Fi Protected Access
WWW—World Wide Web
XML—Extensible Markup Language
Student Study Guide activities for this chapter are available on the Evolve Learning Resources site for this textbook. Please visit http://evolve.elsevier.com/Abdelhak.
When you see the Evolve logo  , go to the Evolve site and complete the corresponding activity, referenced by the page number in the text where the logo appears.
, go to the Evolve site and complete the corresponding activity, referenced by the page number in the text where the logo appears.
Health information infrastructure, technology, and applications
The ideal scenario of a patient experience is one in which, on arriving at the physician’s office, hospital, or another health care setting, he or she is quickly identified as someone who has been seen before. The patient’s previous laboratory tests and imaging results are viewed through the Web browser on a handheld device. Test results, combined with other historical and clinical data already collected into the computer system, are reviewed in minutes. If necessary, data are transferred through a network to a specialist for immediate feedback. The referring physician and the specialist view the information simultaneously while conferring by phone. New treatment is documented and automatically added to a central repository, from which the patient as well as other care providers can retrieve information in the future. Special reminders and flags that alert the physicians about special conditions that need to be investigated, such as abnormal laboratory results and new reports on patient allergies, are automatically presented when the patient’s care information is retrieved. Even reminders for annual immunizations and screening procedures are generated with automatic notification to the patient. In addition, claims for services are automatically processed through computerized systems and forwarded electronically for billing and reimbursement, and the laboratory results from the visit are posted to the patient’s online personal health record. After the visit, the patient can access follow-up test results through his or her computer or mobile device. Scenarios such as this are becoming more accepted, addressing patient and provider expectations regarding health information systems (HISs).
We need more information in health care than ever before. We need to achieve better health care quality outcomes and cost-efficiencies in providing health services. We need to extend access to larger patient populations and health care information to more users. To meet these goals, we are applying new technology in information systems and communications to multiple business processes within the industry. Traditionally, the health care industry did not invest in technology as did other industries, such as banking or retail. However, in the past few years, the health care information technology expenditures have been estimated to be from $17 to $42 billion annually.1 This expenditure is expected to grow from 5% to 7% to 10% to 15% per year. The soar in interest in HISs comes from several factors. In 2003, health care information technology became part of the federal government’s initiative to improve patient safety. To accomplish this, the Office of the National Coordinator for Health Information Technology was created to coordinate the adoption of information technology in hospitals and physician offices across the country.2 (See Chapter 3 for more on this topic.) As part of the American Recovery and Reinvestment Act of 2009, the government has allocated $2 billion to accelerate the adoption of health information technology in the United States. There is also an increasing demand from health care consumers to have more efficient and improved quality of health care. The purpose of this chapter is to describe the current HIS environment, the technology used, the key clinical applications, and the data management tools available. Health information professionals need to develop a greater appreciation of the role and potential of HISs.
The term health information management system serves as an alias for many types of information systems. These include hospital information systems, clinical information systems, decision support systems, medical information systems, management information systems, home HISs, and others. Lindberg, a pioneer in medical information systems, defined a medical information system as “the set of formal arrangements by which the facts concerning the health or health care of individual patients are stored and processed in computers.”3
This chapter begins with a general discussion of the current overall picture of HISs including some of their features, a review of their historical evolution, and what the typical HIS looks like today. The various technologies that support the information infrastructure are described. Computer security and the use of the Internet are discussed. Finally, the role of the health information management (HIM) professional in using these technologies analytically is presented with examples of real-life scenarios. As health information professionals, we need to understand the environment in planning for the future.
Scope of health information systems
It is important to determine the scope of an HIS as well as its components. Each of the components discussed in this chapter can be applied to almost any type of HIS. The scope includes the following:
Departmental—a system limited to a specific clinical or financial domain to serve the business functions of a department (e.g., respiratory therapy, social work)
Intradepartmental—a system that primarily serves the business function of one department but shares information and functions with other departments (e.g., laboratory, patient scheduling)
Hospital (or site of care)-wide—a system that focuses on the integration of the various departmental systems or, in the absence of integration, may provide the primary service for a clinical area
Enterprise-wide—the system that encompasses all of the departmental systems throughout the health system, including hospitals, clinics, nursing homes, and other health facilities
External (cooperative)—a system that is shared among different health systems and primarily exists to report information required by regulatory agencies or as part of a health information exchange (HIE) for regional health information networks (RHIO)
Components
A comprehensive hospital information system contains seven components:
7. Surveillance and related systems that can detect disease at an earlier stage for public health surveillance. This type of system is generally referred to as syndromic surveillance system because it is designed to recognize outbreaks based on the symptoms and signs of infection.4 Because the data used by syndromic surveillance systems cannot be used to establish a specific diagnosis in any particular individual, syndromic surveillance systems must be designed to detect patterns of disease in a population.
In reality, hospital information systems can be viewed along a continuum from the first three major components to acquisition of all seven. Figure 7-1 is a schematic representation of the major categories in a hospital information system and examples of the components. Note that information needed at the time of registration is captured at one level and available at the next level. Components are connected through an interface engine, which is discussed in detail later. The organization relies on the HIS for daily processing activities, including patient care, research, administration, and educational initiatives.
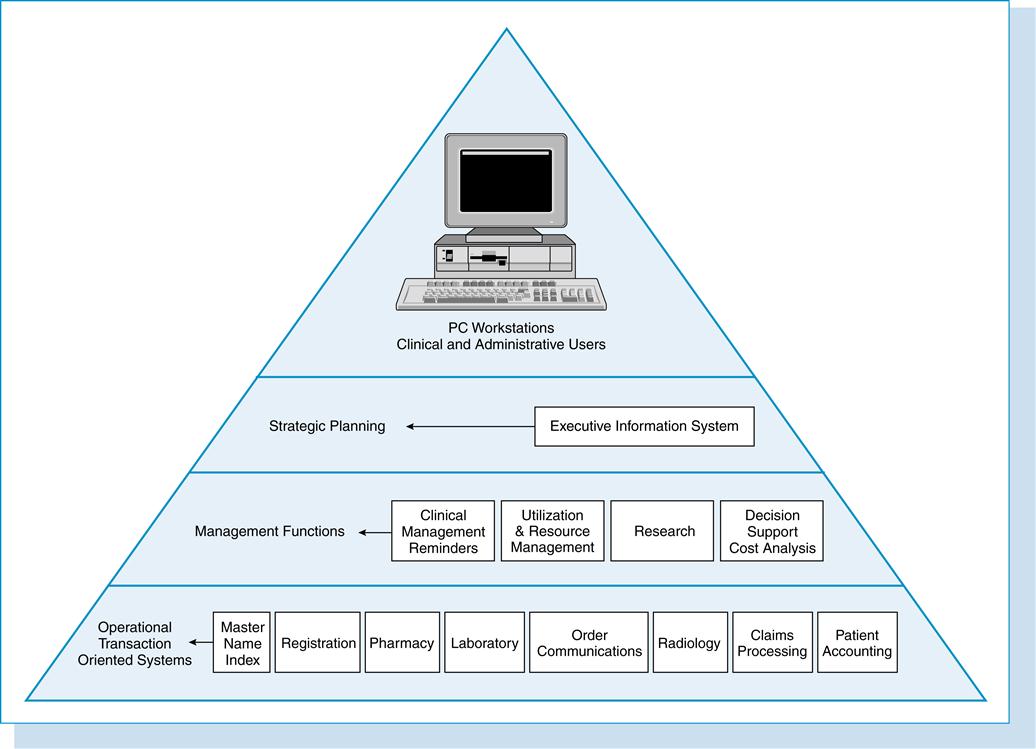
Computers in health care—past and present
Early efforts: 1960s to 1980s
Computers were introduced into the health care arena through punch-card data processing. Early work in epidemiologic and public health applications that performed statistical analysis on the incidence, distribution, and causes of diseases in society provided the early experience with computers. Although some of the early activities were focused on decision making for physicians, many developers worked on building total information systems for hospitals. Also, during the 1960s and 1970s, significant work was undertaken by Octo Barnett at Massachusetts General Hospital in the ambulatory care environment with the development of COSTAR (computer-stored ambulatory record system). The first patient care system that claimed to automate the patient record was initially marketed as the IBM Medical Information Systems Program in the late 1960s and sold until 1972. A number of other companies were involved in patient care information systems during this period, but only the system devised by Lockheed Aircraft, which became the Technicon Data System (TDS), survived for the next 30 years until the product was redesigned and rebranded as electronic health record software used for improving clinical outcomes.5
During the 1970s, HISs were developed in several ways. Many hospitals approached information system development by creating financial information systems and using the same system or slightly modifying the database for clinical applications. Other hospitals adopted a goal of a single integrated system that was designed to use one large database that shared its resources among departments. In contrast, other providers acquired versions of hospital information systems through departmental applications such as a clinical laboratory system to which custom features were later added. The intention was to create common data through a single shared database, but this proved difficult to achieve.6 In large part, database structures and the tools needed to use them were effectively still immature during the 1970s. During this period, hospital databases were derived largely from discharge analysis of medical records. Many hospitals participated through contracts with external computer service organizations by submitting discharge abstracts to the service computer companies for processing and receiving printouts of hospital statistics. The most extensive program was maintained by the Commission on Professional Hospital Activities (CPHA). Its program brought health information professionals into the computer age as they worked with computerized data in new ways. Expectations were expanded as CPHA and others introduced more computing power and offered better ways to retrieve data and provide comparative reports.
As the technology grew to include minicomputers in the 1970s, more and more separate departments were able to acquire departmental systems that met their specific needs. Vendors began to offer packages of functions for hospital departments such as laboratory, radiology, and pharmacy. In addition, software tools emerged that reduced the mystery associated with computers, and clinicians became more interested in leading and participating in computing activities. Minicomputers provided computing power equal to or greater than that of the mainframe computers used previously.
At the end of the 1970s and into the 1980s, the introduction of the personal computer (PC) gave rise to additional empowerment and expectations of clinicians. In effect, technologic advances produced computers that were reliable, small, and low cost. Hardware became reliable and highly affordable. Computer and business communities recognized that the greatest cost involved in information systems development was related to the software. Software engineering emerged as a field dedicated to management of the software development process. The three major computer characteristics of the 1970s were significantly improved reliability and computing power of hardware, availability of more functional software, and reduction in cost of ownership. All this laid a strong foundation for the work to come.
Evolution of hospital information systems: 1980s to late 1990s
In the 1980s, network technology emerged and expanded to enable the departmental systems that began in the previous decade to share and communicate with other systems within the organization. Demographic and associated information on patients who registered in clinics or were admitted to hospitals was now automatically sent to hospital departments so that the data could be incorporated in their database. Admission notices were communicated to dietary, housekeeping, laboratory, radiology, and other ancillary services electronically. In turn, order communications enabled physician orders to be sent from a nursing station directly to an ancillary area. In addition, significant gains were made in building computer networks that linked a variety of diverse applications together.
In 1980, Ball and Jacobs7 described HISs at three levels. A Level I HIS included an ADT application with bed and census reporting, order entry communications, and charge capture and inquiry functions for billing purposes. A Level II HIS focused on systems that included part or most of the patient record. This provided fundamentally clinical databases and improved collection and use of clinical data within these systems. Level III described an HIS in which data were linked to knowledge bases that provided diagnostic support and actual intervention for patient care activities. In these systems, special alerts were made available that responded to specific data content and messages and notified providers through the system.
Late 1990s to present
The prospect for developing health care information systems that are more effective and less costly greatly improved with advances in networking and computer technology. These advances include (1) the emergence of the Internet and World Wide Web (WWW); (2) the development of reliable, scalable servers; (3) the availability of low-cost personal computers, smart phones, and other mobile devices; (4) the introduction of the object-oriented software such as JAVA; (5) the availability of free Internet browsers and utilities; (6) proliferation of data management tools to end users; and (7) the government’s effort in promoting a national health care IT program. This chapter focuses on the use of these advances for health care information systems in general. Chapter 5 includes an in-depth analysis of the electronic health record and the effect of emerging technology on its advances.
Health information systems as a critical discipline
Health professionals from diverse backgrounds work together on medical computing in a variety of ways. Physicians, engineers, administrators, nurses, HIM professionals, software developers, and others have adopted new roles. The study of medical computing is referred to as the academic discipline of medical informatics. In 1990, Greenes and Shortliffe described medical informatics as “the field that concerns itself with the cognitive, information processing, and communication tasks of medical practice, education, and research, including the information science and the technology to support these tasks.”8
Postgraduate training programs are sponsored by the National Library of Medicine for physicians and other health care professionals interested in this field. Physicians usually spend several years after their residency to study medical informatics and work on developing new health care applications and determining how biological sciences intersects with computer technology.9
Today, a number of professional organizations are active in advancing the study of medical and health care informatics. The College of Health Information Management Executives (CHIME), the Health Information Management Systems Society (HIMSS), the American Medical Informatics Association (AMIA), and the American Health Information Management Association (AHIMA) all actively promote the advancement of HISs. The government also sponsors a private–public collaboration called the National eHealth Collaborative (NeHC). NeHC is composed of members from the government and private sector and continues to make recommendations to HHS on how to ensure electronic health records are interoperable while protecting the privacy and security of patient data. (See Chapter 3 for more on this topic.)
Computer fundamentals
To deliver cost-effective and useful HIM systems, we must rely on information technology—hardware, software, and networking—to collect, store, manage, and transmit health information. The following section briefly reviews key concepts in these areas and illustrates their role in health care information systems.
Hardware
Hardware is the physical equipment of computers and computer systems. It consists of both the electronic and mechanical equipment. The computer requires a central processing unit (CPU) with capacity to hold the data being processed as well as the equipment necessary to carry out the system functions. Peripheral equipment including CD-ROMs, flash drives, and tape drives; data input devices such as PCs, tablets, and mobile devices; and output devices such as printers and scanners are also hardware. Computers come in mainframe and micro sizes. Mainframe machines have traditionally been used for large applications that need to support thousands of users simultaneously. Many applications can run on one mainframe. Users interact with the mainframe through terminal emulation software. The user input is transferred to the mainframe computer, where all processing occurs. Microcomputers are based on small microprocessing chips found in individual PCs. They are used for desktop applications such as word processing and spreadsheets and, with the increase in computing power available on the PC, can serve as the hardware for a database management system.
The trend in the industry is to move from a thick-client to a thin-client environment. Thick clients, which might include a desktop PC or a workstation, need a substantial amount of memory and disk space to perform functions that the application may require. Thin clients have minimal or no disk space; they load their software and data from a server and then upload any data they produce back to the server. Thin clients are devices that vary from a laptop computer to a handheld network instrument.
Increasingly, more health care organizations are taking advantage of the use of Grid computing to maximize the use of available hardware. Grid computing is the use of a combination of computer resources from multiple administrative sites (usually other organizations) applied to a common task, which requires a great number of computer processing cycles or the need to process large amounts of data. This type of computing is distributed across large-scale cluster computers as a form of networked parallel processing. The concept is that one organization does not have to have existing resources within its own domain to perform the task but rather can have the “grid” compute the task instead. The main purpose of grid computing is to make the server infrastructure highly scalable. If more resources are needed, this is accomplished by adding more hosts to the existing grid. Grid computing is used extensively to share data and applications for collaborative research at the National Institutes of Health (NIH) including the Biomedical Informatics Research Network (BIRN) and the Cancer Biomedical Informatics Grid (caBIG). These research projects involve functions such as image analysis, data mining, and gene sequencing that are resource intensive. Each laboratory still hosts its own computers, but the grid allows the applications on the local computer to be shared by other members of the consortium.
Another hardware trend is the use of cloud computing. Cloud computing is similar to grid computing in that the processing power can be shared across many computers; however, the hardware is housed by a commercial vendor who specializes in cloud computer hosting. Cloud computing shifts the responsibility to install and maintain the hardware and basic computational service away from the individual laboratory (or hospital) to a cloud vendor. Cloud customers can acquire additional hardware capabilities or software applications upon request to the cloud, perhaps for a specific project. Amazon.com operates a large and popular cloud computing platform called Amazon Elastic Compute Service or EC2.10
Workstations and PCS
The most common devices for data entry, management, and retrieval are personal computers or workstations. PCs can be run independently or connected to an information system to enter and retrieve information. Often times, the PC connects to a clinical application as a virtualized application. A virtualized application is not installed on the PC, although it is still executed as if it is. The application is fooled at runtime into believing that it is directly interfacing with the original operating system and all the resources managed by it, when in reality, it is not. All of the applications, processes, and data used are kept and run on a central server rather than on an individual desktop PC.
A workstation is a type of computer that requires a significant amount of computing power with highly specific graphics capabilities. It is well suited for applications that require more sophisticated memory and graphical displays than a desktop PC. Most workstations function as part of a hospital network or an academic research setting. In the hospital setting, most intensive care unit (ICU) bedside computing is done on workstations because of the need for fast processing (from the monitoring devices) and the graphics resolutions for flow sheets and electrocardiogram (ECG) tracings. However, the differences between PCs and workstations can be fuzzy. A PC with added graphics and memory capabilities might also be used as a workstation.
Network computer
The network computer, which is often called a netbook, is a computer with limited memory and disk storage. Its basic function is to connect to the Internet. This device relies on the server to provide the data and processing power it needs. It is an attractive alternative to PCs and workstations because the hardware is less expensive and easier to install and maintain. Centralized applications reside directly on the server, not the client, so it is not as difficult to maintain the application as it would be for several hundred thick clients. These machines are also called thin clients because the client side of the software requirements is minimal.
Smart phones and mobile devices
A mobile device or personal digital assistant (PDA) is a handheld device that combines computing, fax, and networking features. A typical device can function as a fax sender, e-mail retriever, or network appliance. These devices are lightweight and can be carried in the pocket. They have built-in communications, e-mail, and wireless phone capabilities. The device has either a keyboard for data entry or the use of a touch screen. A PC Tablet is another type of mobile device. It may or may not have a keyboard. It is capable of handwriting recognition so that users can write, using either their finger or a special writing instrument, to store the information in the device. PC Tablets are popular in collecting data directly from patients completing patient satisfaction surveys, for example.
In the health care industry, one example of the use of a mobile device is in home health organizations, in which visiting nurses use mobile devices to record visit encounter data. Another example is the use of a pen-based device to document intravenous therapy data for hospitalized patients. In both examples, the devices are used for daily tasks and are plugged into a “dock,” or receiving component, that transfers the data to a larger computer system. Another example is the use of the mobile device as a resource for information. Most clinicians now have all of the standard reference books at their fingertips through the use of their mobile device.
Storage
The increasing use of clinical applications in health care organizations has caused organizations to examine better solutions for the storage of data. Data retention policies often require the HIM department to store the electronic health record, including scanned images, radiology images, and other documentation for a definite period of time. Hardware RAID (Redundant Array of Inexpensive Discs) is a powerful and inexpensive storage solution that provides much faster disk access while completely protecting against the failure of one (or even two) discs in the physical RAID array. In the event of a physical disc failure, the RAID array is able to be reduced in size to remove the failed disc from the production line while it is being repaired. Typically, a system administrator can replace the failed drive without bringing down the array and without interruption to users. The array then rebuilds the array incorporating the new disc, and performance returns to normal. Data written on RAID is protected from physical hard drive failure.
Another type of storage solution is a SAN (Storage Area Network). A SAN is a more expensive implementation of RAID hosted on a dedicated device which can accommodate large numbers of physical drives in a single array. This array presents as a single unit of space that can be subdivided as desired. SANs are fast, flexible, expandable, and robust.
Voice recognition
A voice recognition system consists of both hardware and software. It is included in this section on hardware because it is primarily an alternative to a data input device. A voice recognition system can recognize spoken words. It is an attractive technology for health care applications because it offers the most efficient means for practitioners to incorporate data capture into their normal routines. Voice recognition means that the computer can record information that is being said. It still does not understand what is being said, and it is important to be aware of this distinction.
This technology has grown phenomenally in recent years, particularly with continuous-speech systems. Continuous speech means that the user can use the system naturally and does not have to speak as slowly and distinctly as with previous systems. Most systems require an initial training session in which the software is taught to recognize the user’s voice and dialect. Successful implementation of this type of system is heavily dependent on the user. An effective use of this technology is in emergency departments and radiology departments, where transcribed reports need fast turnaround. Sometimes the voice recognition software is combined with templates so that the user has to speak only to complete the blank spaces in a template and not the entire document. Software for voice recognition can exist on an individual PC or be a shared application across a network. Voice recognition is also being used to offer clinicians a way to immediately dictate, sign, and produce a report independently. In other settings, voice recognition is turned on while an individual clinician dictates. The transcriptionist receives a draft document as well as the voice version and is more quickly able to complete the document and present it for signature.
Software
Software is the set of instructions required to operate computers and their applications. Software includes programs that are sets of instructions that direct actual computer operating functions, called the operating system, and sets of instructions used to accomplish various types of business processes, known as application software. Software written to process laboratory orders is application software. These instructions are combined to direct the overall functions of a given information system. The operating system directs the internal functions of the computer. It serves as the bridge to application programs. Without an operating system, each programmer would have to program all the detail involved in receiving data, displaying graphics on a screen, sending data to printers, and so forth. Operating systems contain all of the standard routine directions that handle such tasks. Operating systems act as system managers that direct the execution of programs, allocate time to multiple users, and operate the input/output (I/O) devices as well as the network communication lines. With the increase in distributed computing, most operating systems are now able to run independently of the hardware platform. An example of an operating system is UNIX. UNIX and flavors of UNIX can run on mainframes as well as workstations. UNIX is capable of running a number of powerful utility programs to support Internet applications while allowing multiuser access and file-sharing capabilities.
Programming languages
Programming languages refer to the various sets of instructions developed to operate applications and to generate instructions themselves. Software has developed significantly since the 1980s, and the evolution of new generations of programming languages has enhanced the use and rapid development of computing power. Generally speaking, all instructions to computers are ultimately expressed in their native codes, known as machine language. This most basic level of programming refers to the system of codes through which the instructions are represented internally in the computer. To illustrate, a programmer writing in a computer’s low-level machine language uses machine instructions (mostly all numbers) to address memory cells for storing data, accumulators to add and subtract numbers, and registers to store operands and results. Some codes represent instructions for the central processor, some codes move data from the accumulator into the main memory, some codes represent data or information about data, and some codes point to locations (addresses) in memory.
The second-generation programming languages built on machine codes by the invention of a symbolic notation called assembly language. Assembly language used key words to invoke sets of machine instructions instead of the numeric ones needed in the machine language. Terms such as “Add” or “Load” represented specific sets of key word machine instructions. All of the assembly languages vary by type of machine or CPU. An assembly language program is written for a specific operating system and hardware platform. It needs to be rewritten for a new operating system. It is one step closer to human language than machine language.
Third-generation programming languages extended the efficiency of programmers by offering the capability to write programs in languages that were shorter and quicker to write. They combined more and more of the machine-level instructions to accomplish their tasks. This generation of language also introduced a new capability. Some could run on different operating systems. Examples of third-generation programming languages are FORTRAN (Formula Translator), COBOL (Common Business-Oriented Language), and C.
One third-generation programming language, MUMPS (Massachusetts General Hospital Utility Multi-Programming System), was established for specific use in health care applications. MUMPS was established in the late 1960s and is still used today in both health care and other industries. It has been renamed the M Programming Language. Both the Departments of Defense and Veterans Affairs have installed nationwide medical information systems using MUMPS as the primary language.11
Fourth-generation languages with even greater efficiencies enable programmers to use instructions at a higher level. These types of programs are commonly known as 4GL. The concept is that program generators—sets of instructions that can be invoked as components when needed—are the foundation of the language. This allows the programmer to focus more on the logic of the program (application servers in the three-tier client server) and less on the instructions to the computer. In other words, the program generator is able to determine the lower level instructions necessary to generate the output. 4GLs were designed for powerful data manipulation and the capability of developing code that can be reused in other applications. 4GLs are often proprietary to one vendor.
Databases
A database is a collection of stored data, typically organized into fields, records, and files. A database management system (DBMS) is an integrated set of programs that manages access to the database. Databases have evolved with advances of technology. The goal of the database is to represent the lowest level meaning of the data that allows users to retrieve and manipulate the data. A database model is a collection of logical constructs used to represent the data structure and the relationships between the data. The four major database models are:
Database models
Relational model
The relational model, the most popular database model, was developed by E. F. Codd in 1970.12 It is designed around the concept that all data are stored in tables with relationships between the tables. A relation is created by sharing a common data element; for example, if two tables have a patient identifier, patient identifier relates those tables. How the data are physically stored is not of concern to the user. The user needs to know only what the relationships are between the entities in the database.
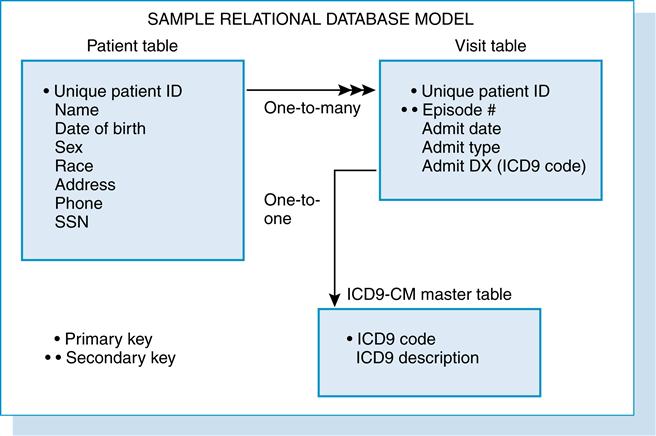
Figure 7-2 shows an example of three tables in a relational database used in an ambulatory clinic. The rules for a relational database used in an ambulatory clinic are as follows:
1. Each patient has only one entry in the patient table and is identified by a unique identifier.
2. Each patient has one or more entries in the visit table.
3. Each patient in the visit table is linked to the patient table by the unique identifier.
4. Each working diagnosis entry in the visit table has a lookup entry in the diagnosis master file.
The rules listed in Figure 7-2 are defined as the associations among the data. There are three types of relationships to describe associations:
There are several reasons for choosing the relational model for this ambulatory clinic application. First, we want to store the data only once. By creating a primary key for the unique patient identifier, we can eliminate storing the patient’s name and other demographics in the visit table. We can always join the patient and visit table by patient identifier and report the data in both tables. Second, this application requires several master or lookup tables. Lookup tables enable data translations to be stored outside the visit and patient tables. In the preceding example, the visit table contains only the visit working diagnosis code (most often an ICD-9-CM code). The diagnosis lookup table stores two fields, the ICD-9-CM code and ICD-9-CM description. Each code and description is in the diagnosis lookup table only once. In this way, the ICD-9-CM description does not have to be stored in each visit record.
Structured query language
Structured Query Language (SQL) is the relational database model’s standard language. It is pronounced “see-kwell” or as separate letters S-Q-L. It was originally designed in 1975 by IBM but has since been adopted by the American National Standards Institute (ANSI). SQL commands allow the creation and management of a database and provide a method of retrieval of data. All queries are based on the SELECT statement (see the following example of these queries).
Example of Queries Based on the SELECT Command
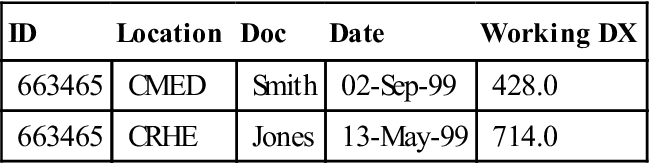
Using the relational database illustrated in Figure 7-2, the Standard Query Language query to list all of the visits for a patient with patient identifier 663465 is
SELECT FROM VISIT
WHERE PATIENTID=‘663465’;
where instructs all fields in the visit table to be printed. The output from the query would be
000000
Location
Smith
00-May-00
Working
| ID | Location | Doc | Date | Working DX |
| 663465 | CMED | Smith | 02-Sep-99 | 428.0 |
| 663465 | CRHE | Jones | 13-May-99 | 714.0 |
Hierarchical model
The hierarchical model differs greatly from the relational model. The hierarchical model supports a treelike structure that consists of parent (or root) and child segments. Each parent segment has a child. Each child segment can have only one parent segment. However, a parent can have more than one child. A user queries the database, and the search seeks the answer from parent to child. The answer to the query is found by matching the conditions by searching downward through the tree. Retrieving involves gathering the parent record and following a pointer to the record in the next lower level. This model is quite effective when the queries are predetermined and pointers already identified. It is not effective for ad hoc queries or when there is information only about the data contained in the child segment. This model requires the user to understand the physical as well as the logical structure of the database. Because the logical model is replicated in the physical structure, it is difficult to change this structure. Many-to-many relationships (as described earlier) are difficult to represent in this model. It is also difficult to use the data for multiple purposes. If another type of query is needed, additional copies of the database need to be made so that the logical model can be changed to the copied database.
An example of a hierarchical database is found in hospital patient accounting systems. The system contains many patient accounts (parent) that in turn have many transactions (child). The total number of transactions is likely to be greater than 50. The rules would be:
• Each patient account (parent) has at least one transaction (child).
• Each patient account can have many transactions.
A common user query would be to determine a patient’s total charges. This model would easily handle that because the patient account (parent) is known. It would identify the parent and then trace the pointers to each of the transactions (child). However, it would be difficult in this model to determine all of the patients who had a specific transaction during the past year.
Network model
The network model is similar to the hierarchical model except that a child can have more than one parent. In a network database, the parent is referred to as an owner and a child is referred to as a member. In other words, it supports the many-to-many relationship. It does not, as the name might suggest, refer to the physical configuration of the computer where the database resides but instead describes the logical arrangement of the data.
Object-oriented model
This model has experienced a surge in popularity due to the use of JAVA and other programming tools. The database is one that embraces the concept of an object. An object-oriented database is a collection of objects. Objects support encapsulation and inheritance. Encapsulation is the technique through which an object such as a patient is defined with certain characteristics. The user does not need to know how the characteristics are stored, just that the object “patient” exists and has certain attributes. Inheritance means that one object can inherit the properties of another object. For example, a physician is defined as an object with certain characteristics (a name, a specialty, an office address). A resident is defined as another object with certain characteristics with the first characteristics being those of a physician. Therefore, the resident inherits the properties of the physician object. There are no primary keys in an object-oriented model. Access to data can be faster because joins are often not needed as in the relational model. This is because an object can be retrieved directly without a search, by following pointers.
Network technology
Network technology is used within individual organizations to connect the PCs, workstations, printers, and storage devices to the organization’s network and the entire outside world. It has evolved from the basic terminal to mainframe computer connection to local and wide area networks and the client-server technology. A local area network (LAN) connects multiple devices together via communications and is located within a small geographic area. An example of a LAN environment is a patient scheduling system at a primary care clinic in which seven PCs are connected to a server. Each of the PCs is able to execute its own programs (e.g., word processing, spreadsheet applications) but is also able to access data and devices anywhere on the LAN. This allows all users of the LAN to share hardware such as laser printers and scanners as well as to share patient files. Users can also use the LAN to communicate with each other via e-mail or share schedule and appointment books. LANs are capable of transmitting data at a high rate, making access to the LAN resources seem transparent to the user. However, there is a limit to the number of computers that can attach to a single LAN.
The most widely used LAN network topology in use today is Ethernet. Developed at Xerox in 1976, Ethernet is a standard defined by the Institute of Electrical and Electronics Engineers (IEEE) as IEEE 802.3. This standard defines the transmission speed of data traveling across the LAN as either 10 million bits per second (Mbps) or 100 Mbps. The topology is designed with messages that are handled by all computers in the LAN until they reach their final destination. The disadvantage of this technology is that a failure in one segment of the network affects the entire LAN. Another type of LAN technology is token ring. Token ring (IEEE 802.5) means that the transmissions travel from one computer to another until they reach their final destination. This allows a single computer to be added to or disconnected from the network without affecting the rest of the computers on the LAN. Token ring transmission speeds vary from 4 to 16 Mbs.
Wide area networks (WANs) are used for extensive, geographically larger environments. They often consist of two or more LANs connected through a telephone system, a dedicated leased line, or a satellite. The Internet is an example of a WAN. WANs are usually found in organizations that need to connect computers across an entire health care delivery system. For example, the hospital, the long-term care facility, and the physician office all have an internal LAN in their own areas, and the LAN is connected to the backbone of the WAN.
The most widely used WAN technology today is the fiber distributed data interface (FDDI). FDDI provides transmission at a higher rate than Ethernet or token ring. It is run with fiber-optic cable. There are hundreds to thousands of smooth, clear, thin, glass fiber strands bound together to form fiber-optic cables. Data are transformed into light pulses that are emitted by a laser device. Current fiber-optic technology can transmit data at speeds of up to 2.5 gigabits per second, much faster than Ethernet or token ring.
A popular type of network found in health care today is a wireless or Wi-Fi network. This type of network enables computers and other handheld devices to communicate with the Internet and other network servers without being physically connected to the network. Wireless networks use the IEEE 802.11 standard which was ratified in September 1999. There are several versions of the 802.11 protocol in use, with the most commonly used being 802.11g.
Each wireless network has a service set identifier (SSID). This is a code attached to all packets on a wireless network to identify each packet as part of that network. The code consists of a maximum of 32 alphanumeric characters. All wireless devices attempting to communicate with each other must share the same SSID. SSID also serves to identify uniquely a group of wireless network devices used in a given Service Set. For security purposes, it is important to change the default, factory-assigned SSID for each wireless network. The default SSID will identify your network location and potentially permit others to access your network.
To secure wireless networks, protocols were created to encrypt and protect wireless transmissions. One of the first protocol systems developed is the Wired Equivalent Privacy (WEP) system, and it is part of the IEEE 802.11 standard. It provides an encryption scheme so that the information transmitted over a wireless network is protected as it is sent from one device to another device. Because of some weakness in the WEP protocol, Wi-Fi protected access (WPA) is the most popular method of securing wireless networks. Data is encrypted as it travels over the wireless network as with WEP but the method of securing the network greatly improved with WEP. A major improvement is the requirement that the authentication code used dynamically changes as the system is used. In previous versions, the same code was used with each transmission, and so once the code was known by the outside, the network was compromised.
Wi-Fi’s greatest strength is also a weakness. Every action that is performed while connected to a wireless network is broadcast to any other network within a certain distance. Therefore, it is important to secure each wireless network with encryption. Encryption is discussed in a later section in this chapter.
Wired versus wireless comparison
Several protocols are available for communicating across networks. A protocol is a specification or algorithm for how data are to be exchanged. It is similar to the telephone system, which expects an area code as part of the phone number. Two of the more popular network protocols are TCP/IP and ATM. TCP/IP is the acronym for Transmission Control Protocol/Internet Protocol. This protocol is the standard used to connect Internet sites. TCP/IP can run on various platforms and can connect hardware systems of different types as long as both systems support TCP/IP. It divides each piece of data that is to be sent across the network into packets, and the packets are then sent to the destination via the most available route at the time of transmission. TCP/IP allows packets to be rerouted if the network is particularly busy at one site. ATM is the acronym for Asynchronous Transfer Mode. ATM creates a fixed path between the source and destination. The packets are of a fixed size. The benefit of this type of network is that a single packet does not overload the network, and very fast transmission is supported. It can relay images, sound, and text at high speeds. Table 7-1 illustrates the differences between wired and wireless networks.
Table 7-1
WIRED VERSUS WIRELESS COMPARISON
| Ethernet (Wired) | Wi-Fi (Wireless) | |
| Advantages | Very secure; reliable transfer of data; data transfer speeds up to 94 Mbps | No cables to connect to device; minimal installation costs; allows for access to the network from any location |
| Disadvantages | Does not permit mobility; installation costs can be high for cable routing | Extra process required to secure network; some areas may not be reachable by wireless; data transfer rates are slower than Ethernet |
| Cost | Network cards, cables, and labor costs of installation | Network cards (although some PCs have technology built in) |
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


