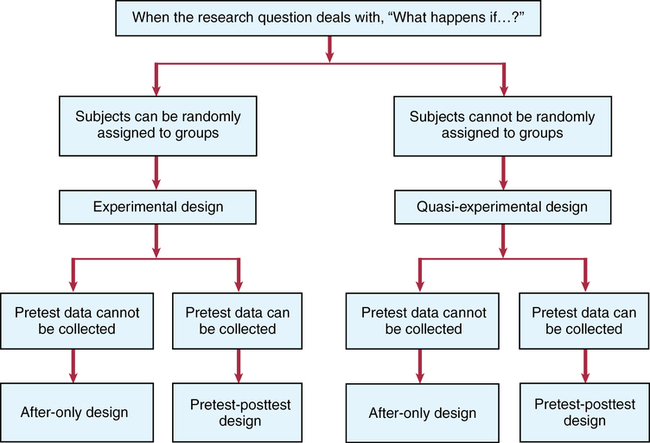
CHAPTER 9 Susan Sullivan-Bolyai and Carol Bova After reading this chapter, you should be able to do the following: • Describe the purpose of experimental and quasi-experimental research. • Describe the characteristics of experimental and quasi-experimental studies. • Distinguish the differences between experimental and quasi-experimental designs. • List the strengths and weaknesses of experimental and quasi-experimental designs. • Identify the types of experimental and quasi-experimental designs. • List the criteria necessary for inferring cause-and-effect relationships. • Identify potential validity issues associated with experimental and quasi-experimental designs. • Critically evaluate the findings of experimental and quasi-experimental studies. • Identify the contribution of experimental and quasi-experimental designs to evidence-based practice. Go to Evolve at http://evolve.elsevier.com/LoBiondo/ for review questions, critiquing exercises, and additional research articles for practice in reviewing and critiquing. One purpose of scientific research is to determine cause-and-effect relationships. In nursing practice, we are concerned with identifying interventions to maintain or improve patient outcomes, and we base practice on evidence. We test the effectiveness of nursing interventions by using experimental and quasi-experimental designs. These designs differ from nonexperimental designs in one important way: the researcher does not observe behaviors and actions, but actively intervenes by manipulating study variables to bring about a desired effect. By manipulating an independent variable, the researcher can measure change in behaviors or actions, which is the dependent variable. Experimental and quasi-experimental studies are important to consider in relation to evidence-based practice because they provide the two highest levels of evidence (Level II and Level III) for a single study (see Chapter 1). Experimental designs are particularly suitable for testing cause-and-effect relationships because they help eliminate potential threats to internal validity (see Chapter 8). To infer causality requires that these three criteria be met: • The causal (independent) and effect (dependent) variables must be associated with each other. • The cause must precede the effect. • The relationship must not be explainable by another variable. The purpose of this chapter is to acquaint you with the issues involved in interpreting and applying to practice the findings of studies that use experimental and quasi-experimental designs (Box 9-1). The Critical Thinking Decision Path shows an algorithm that influences a researcher’s choice of experimental or quasi-experimental design. In the literature, these types of studies are often referred to as therapy or intervention articles. A true experimental design has three identifying properties: A research study using a true experimental design is commonly called a randomized controlled trial (RCT). In hospital and clinic settings, it may be referred to as a “clinical trial” and is commonly used in drug trials. An RCT is considered the “gold standard” for providing information about cause-and-effect relationships. An individual RCT generates Level II evidence (see Chapter 1) because of reduced bias provided by randomization, control, and manipulation. A well-controlled design using these properties provides more confidence that the intervention will be effective and produce the same results over time (see Chapters 1 and 8). Box 9-2 shows examples of how these properties were used in the study in Appendix A. Randomization, or random assignment, is required for a study to be considered a true experimental design with the distribution of subjects to either the experimental or the control group on a purely random basis. As shown in Box 9-2, each subject has an equal chance of being assigned to either group, which ensures that other variables that could affect change in the dependent variable will be equally distributed between the groups, reducing systematic bias. It also minimizes variance and decreases selection bias. Randomization may be done individually or by groups. Several procedures are used to randomize subjects to groups, such as a table of random numbers or computer-generated number sequences (Suresh, 2011). Whatever method is used, it is important that the process be truly random, that it be tamperproof, and that the group assignment is concealed. Note that random assignment to groups is different from random sampling as discussed in Chapter 12. Control refers to the process (described in Chapter 8) by which the investigator holds certain conditions constant to limit bias that could influence the dependent variable(s). Control is acquired by manipulating the independent variable, by randomly assigning subjects to a group, by using a control group, and by preparing intervention and data collection protocols to maintain consistency for all study participants (see Chapter 14). Box 9-2 illustrates how a control group was used by Thomas and colleagues (2012; see Appendix A). In experimental research, the control group receives the usual treatment or a placebo (an inert pill in drug trials). Box 9-2 provides an illustration of how the three major properties of true experimental design (randomization, control, and manipulation) are used in an intervention study and how the researchers ruled out other potential explanations or bias (threats to internal validity) for the results. This information will help you decide if the study may be helpful in your own clinical setting. The description in Box 9-2 is also an example of how the researchers used control (along with randomization and manipulation) to minimize bias and its effect on the intervention (Thomas et al., 2012). This control helped rule out the following potential specific internal validity threats (see Chapter 8; not to be confused with instrument threats to validity, described in Chapter 15): • Selection: Representativeness of the sample contributed to the results versus the intervention • History: Events that may have contributed to the results versus the intervention • Maturation: Developmental processes that can occur that potentially could alter the results versus the intervention • Use an experimental and control group, sometimes referred to as experimental and control arms. • Have a very specific sampling plan, using clear-cut inclusion and exclusion criteria (who will be allowed into the study; who will not). • Administer the intervention in a consistent way, called intervention fidelity. • Typically, carry out statistical comparisons to determine any differences between groups. It is important that researchers establish a large enough sample size to ensure that there are enough subjects in each study group to statistically detect differences between those who receive the intervention and those who do not. This is called the ability to statistically detect the treatment effect or effect size (see Chapter 12); that is, the impact of the independent variable/intervention on the dependent variable. The mathematical procedure to determine the number for each arm (group) needed to test the study’s variables is called a power analysis (see Chapter 12). You will usually find power analysis information in the sample section of the research article. For example, you will know there was an appropriate plan for an adequate sample size when a statement like the following is included: “A purposive sample of 249 patients were enrolled. A target sample of 61 per group was selected to achieve a power of at least 80% for detecting group differences in mean change scores” (Sherman et al., 2012). Thus, this information shows you that the researchers sought an adequate sample size. This information is critical to assess because with a small sample size, differences may not be statistically evident, thus creating the potential for a type II error; that is, acceptance of the null hypothesis when it is false (see Chapter 16). Carefully read the intervention and control group section of an article to see exactly what each group received and what the differences between groups were. In Appendix A, Thomas and colleagues (2012) offer the reader a detailed description and illustration of the intervention. The discussion section reports that the patients’ in-the-moment priorities may have posed a challenge to adhering to the attitudinal content in the intervention group. That is the kind of inconsistency that should make you wonder if it may have interfered or influenced the findings. In summary, when reviewing RCTs, carefully assess how well the study incorporates fidelity measures. Fidelity covers several elements of an experimental study (Bellg et al., 2004; Gearing et al., 2011; Keith et al., 2010; Preyde & Burnham, 2011; Santacroce et al., 2004) that must be evaluated and that can enhance a study’s internal validity. These elements are as follows: 1. Framework of the study should be considered (e.g., Did the study have a well-defined intervention and procedures? Were the study participant characteristics and environment well described?). 2. Intervention fidelity involves the process of enhancing the study’s internal validity by ensuring that the intervention is delivered systematically to all subjects in the intervention group. To enhance intervention fidelity, researchers develop a system for evaluating how consistently the intervention was carried out by those delivering the intervention. This system includes a procedure manual that provides for well-defined program objectives, including a definition of the treatment dose; consistent training of the interventionists and all research staff; standardized data collection procedures and/or supervision consisting of frequent review of the intervention by observing, videotaping, or audiotaping the sessions; troubleshooting problems; cultural considerations for the intervention; ongoing training and supervision of interventionists; and corrective feedback measures (see Chapter 8). 3. Consideration of internal and external validity threats.
Experimental and quasi-experimental designs

Research process
True experimental design
Randomization
Control
Manipulation
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Experimental and quasi-experimental designs
Get Clinical Tree app for offline access
