A brief history of genetics
Genes and chromosomes
The structure of DNA and RNA
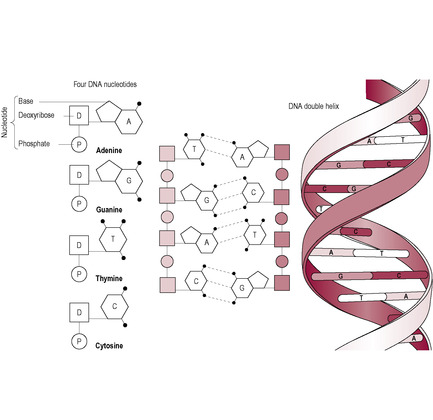
Fig. 7.1
DNA replication and cell division
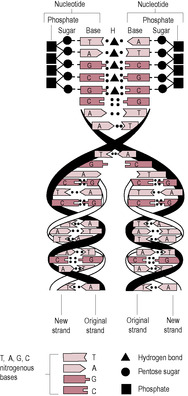
Fig. 7.2
Mitosis
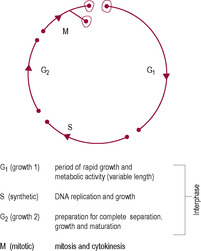
Fig. 7.3
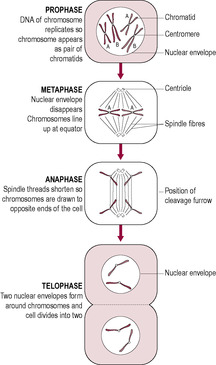
Fig. 7.4
The genetic message
Transcription
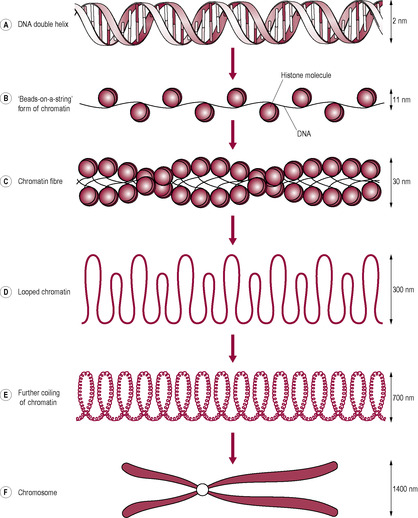
Fig. 7.5
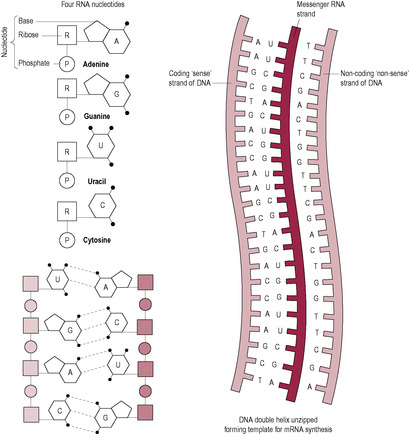
Fig. 7.6
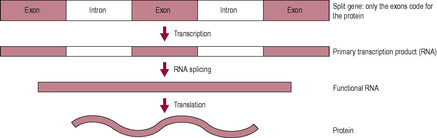
Fig. 7.7
Protein synthesis
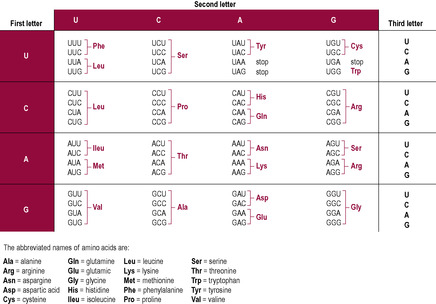
Fig. 7.9
Mutation
Meiosis
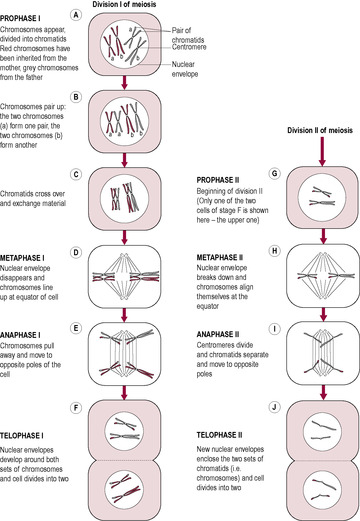
Fig. 7.11
Disorder
Example
Incidence
Outcome
Notes
Polyploidy
Triploidy 69 chromosomes (69,XXX, 69,XXY, 69,XYY)
Occurs in 2% of conceptions but early spontaneous abortion is normal
Lethal
Usually arises from fertilization of oocyte by two sperm or from a diploid gamete. 69,XXY is most common. Polyploid cells occur normally in the bone marrow and liver as a stage of cell division
Trisomy
Trisomy 13
1/5000 live births
Patau’s syndrome
Usually due to non-disjunction of chromosomes or chromatids at anaphase. Trisomy increases with increased maternal age and is sometimes associated with radiation or viral infection. There may be a familial tendency
Trisomy 18
1/3000 live births
Edward’s syndrome
Maternal age effect. Incidence at conception much higher – most affected fetuses abort spontaneously. More female fetuses seem to survive
Trisomy 21
1/700 live births
Down’s syndrome
Incidence at conception is higher. Maternal age effect; the extra chromosome is maternal in 85% cases. The most serious complications are mental handicap and congenital heart problems
47,XXY
1/1000 male births
Klinefelter’s syndrome
Trisomies involving sex chromosomes usually result in a less serious outcome. Condition is usually diagnosed during investigations for infertility
47,XYY
1/1000 male births
Often asymptomatic, some effects on IQ. Only XX and XY offspring observed
Monosomy
Monosomy X
1/5000 female births, much higher at conception
Turner’s syndrome
Due to non-disjunction in either parent; 80% of affected females have maternal X so it is the paternal chromosome that is missing
Deletion and ring chromosome
Wolf–Hirschhorn syndrome (partial deletion of short arm of chromosome 4) Cri du chat syndrome (partial deletion of short arm of chromosome 5)
Incidence of deletions and/or duplications is 1/2000 births
Chromosome imbalance of autosomes is usually associated with mental retardation and multiple dysmorphic features
A deletion is the loss of part of chromosome. A ring chromosome is due to deletions in both arms of a chromosome and the fusion of the proximal sticky ends. Microdeletions are deletions that can just be detected by light microscopy
Duplication
Duplication is where there are two copies of a segment of chromosome. This is more common and less harmful than deletions
Inversion
The carriers of balanced inversions and translocations are healthy because the cells have all the genetic material but gamete formation is affected so there is a high rate of miscarriage and malformation
A segment of the chromosome is inverted through 180° between breaks
Usually does not cause clinical problems but unbalanced gamete may result
Translocation
Reciprocal
Translocations involve transfer of chromosomal material between chromosomes. Two chromosomes are broken and repaired abnormally or there is recombination between non-homologous chromosomes at meiosis. Reciprocal translocations involve transfer of material between two chromosomes
Robertsonian (centric fusion)
Robertsonian translocation involves transfer of material, which leaves a large chromosome, and a fragment of a chromosome, which is unable to replicate; most common centric fusion translocations are 13/14 and 14/21. Balanced carriers have 45 chromosomes and are healthy. Gametogenesis is affected
Autosomes and sex chromosomes
Sex chromosomes
Alleles
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Overview of human genetics and genetic disorders
As part of the routine antenatal care, which Zara is receiving from her midwife at her local maternity unit, Zara is offered a 20-week anomaly ultrasound as part of the screening policy of the local maternity services. This scan examines the physical structures of the baby and enables a skilled ultrasonographer to identify major structural abnormalities of the internal organs and other signs of structural problems such as polyhydramnios, oligohydramnios, placental abnormalities and so on. Often the presence of a number of abnormalities (frequently referred to as a syndrome) could indicate the presence of many possible genetic disorders.
Zara is quite upset because one of her friends has just undergone amniocentesis as her ultrasound scan had revealed cardiac, brain and limb abnormalities. Zara’s scan appears to be normal and the baby appears to be growing well but Zara is still concerned that all may not be well and wishes to discuss what further tests are available that would reassure her all is well.
• How would you, as Zara’s midwife, reassure and counsel her and James through this difficult period?
Within living organisms, the genetic information is usually carried in chromosomes where organization of the DNA provides a gene or ‘blueprint’ (genotype) directing protein synthesis and thus the expression of the genes into physical characteristics (phenotype). Characteristics are passed from one generation to the next in the form of genes. In sexually reproducing species, the genes are shuffled and repackaged into the gametes. Variations between genes affect survival so the individuals with the best-adapted characteristics to cope with environmental conditions have an advantage. This is described as natural selection. Although DNA codes for the genes, not all the genes are expressed in any one cell or any one time. The phenotype is determined by which genes are expressed (turned on) and which are not. Epigenetics is the term used to describe the modifications to DNA which controls which genes are expressed. As well as the functions of the genes being identified as part of the determination of the DNA sequence (human genome), thousands of small non-coding RNAs have roles in mRNA stability, protein translation, protein modification and changes in the germline. All eukaryotic organisms (animals) have both nuclear DNA and mitochondrial DNA (mtDNA) (outside the nucleus) which is probably due to a serendipitous event in evolution whereby ancestral bacterial forebears of mitochondria were incorporated into eukaryotic cells (see Chapter 1).
The study of genetics focuses on inherited characteristics, particularly those that are considered abnormal, how these arise and their effects on the individual. Genetics is a predictive science and its rules are based upon the application of mathematical statistics and probability. Evolutionary effects on genetics may determine the penetration of recessive genetic disorders such as cystic fibrosis into gene pools. The impact of genetics upon antenatal screening to predict the probability of fetal abnormalities is of particular relevance for midwives.
Historically, humans unknowingly but successfully applied genetics to the breeding and domestication of animals and plants. However, the first systematic study of genetic interactions is associated with the breeding experiments of Gregor Mendel, an Austrian monk, in the 1860s. Mendel established inheritance patterns of certain traits in pea plants and demonstrated that application of statistics to inheritance could be very useful. Subsequently, more complex forms of inheritance have been identified.
Mendel correctly identified the concept of genes long before the structures of DNA and chromosomes were understood. He proposed that ‘particles of inheritance’ were transmitted from one generation to the next and defined a concept that he described as an allele. The term ‘allele’ is now used to describe a specific variant or alternative form of a particular gene occupying a given locus (position) on a chromosome.
The term ‘eugenics’ was coined by Francis Galton (a cousin of Charles Darwin) who advocated that application of Darwinian theories and selective breeding could improve the quality of entire populations, particularly with respect to talent and intelligence. In the late nineteenth century, eugenics societies formed in various parts of the world sought to promote such practices as marriage restriction, sterilization and custodial commitment of those thought to have unwanted characteristics and positively encouraging reproduction in those individuals perceived as the best and brightest. The popularity of the eugenics movement was already waning when infamous eugenics programmes of Nazi Germany were revealed at the end of World War II.
Darwin’s ‘survival of the fittest’ theory promoted the concept of natural selection and how environmental conditions determine survival and reproduction of organisms with particular traits. If environmental conditions do not vary much, these traits continue to be adaptive and become more common within the population.
Neo-Darwinism (or ‘modern evolutionary synthesis’) extends the scope of Darwin’s ideas of natural selection by including modern genetic knowledge about DNA and concepts such as speciation, kin selection and altruism. It advocates that survival of a species is not necessarily by the fittest but by those that are most likely to reproduce successfully. This is reflected in the work of William Hamilton, popularized by Richard Dawkins, who asserted that the gene, rather than the organism or species, is the true unit of reproduction and the primary driver and beneficiary of evolution. The genes are provocatively described as ‘selfish’ because in order to replicate and be successful they use organisms that contain them solely as vehicles to ensure survival (1989). Obviously, reproduction is vital to ensure that the genes survive.
This controversial view portrays organisms solely as mechanical methods of survival to pass genes on to as many offspring as possible. However, there are a number of arguments against this view. Organisms are not perfectly adapted; for instance, humans seem to have some non-advantageous genes such as those coding for the vermiform appendix. It could be argued that these genes have not been obliterated because other linked genes are advantageous and effectively protect them. The other important point is that species not only interact with their environment but also positively alter their environment to optimize survival. The selfish gene hypothesis also accounts for how genes that seem to be harmful can evolve by natural selection (Badcock and Crespi, 2008).
The environment interacts with genes (the nature/nurture debate) and has a tremendous influence on how they are expressed, affecting susceptibility and resistance to disease. Genes may act in competition with each other, which may explain certain pathophysiological conditions and their aetiology. Some organisms may use their genes to alter the phenotype of another animal to increase their chances of survival. For example, infection with the trematode parasite causes its snail host’s shell to become thicker (Dawkins, 1999). Co-evolution explains how the change of one organism can be linked to the change in a related organism. Each organism exerts selective pressure on the adaptation and evolution of the other. Examples include how angiosperm (flowering trees) and primates evolved, the existence of mitochondria in eukaryotic cells (see Chapter 1) and co-evolution of parasites with the acquired immunity of their hosts. Epigenetics and genetic imprinting (see p. 164) explain how gene expression can be affected by the environment.
Within the modern medical world there now exist ethical dilemmas surrounding the screening for, detection of and termination of abnormal fetuses. Current research in genetics is not solely medical (Box 7.1) as it can be applied to population studies, such as tracing the origins of human migration movements, and to genealogy, such as tracing the real families of children of the Argentinean ‘Disappeared’ (Jones, 1994) and the route the early Polynesians took to reach New Zealand (Sykes, 2001).
Box 7.1
• Screening for fetal abnormality
• Genetic counselling for parents with a family history of genetic disorders
• Identification of fetal sex in the early (indifferent) embryological phase
• Cloning of whole organisms
• Gene manipulation not only to eradicate disease but also to improve existing disease states
• Treatment by gene manipulation in animals to produce human proteins, hormones and so on
• Genetic modification
• Identification of individuals by genetic ‘fingerprinting’
Genes are the units of inheritance. Each gene is a length of DNA on a chromosome that contains the coded information to direct the synthesis of a specific protein chain. The differences between organisms are related to different proteins being synthesized that have different structures and functions. Effectively the genes act as a blueprint, or instruction manual, for the total development of the organism and how it will function and change during its lifetime (Box 7.2). Chromosomes are packages of DNA in the nucleus, on which the genes are linearly arranged. Chromosomes have two arms: a shorter p arm and a longer q arm, with a centromere between them. Chromosomes are important in cell replication and the passing of the genetic message from one generation to the next. Usually the DNA, about 180 cm per nucleus, exists as an unstructured mass of threads in the nucleus. However, when the cell is undergoing division the DNA becomes organized and compacted into chromosomes, which can be visualized by microscopy (see Chapter 1). This chromosomal organization allows biologists to identify genes and localize them to a particular chromosome to follow their pattern of inheritance. Each cell has the same genetic information in its nucleus as the original zygote (fertilized ovum) and all of the cells derived from it. Different cells behave in different ways because they express different subsets of information from the DNA.
Box 7.2
Genetics can be considered as a language based on the DNA molecule. Linguistic development and evolution have a number of similarities. Studies looking at the origins of a particular word and how it has evolved to be slightly different in different languages are similar to the changes in genes (Jones, 1994). Genetic mutations are analogous to new words being introduced into the language (such as ‘email’).
• Language = genetics
• Vocabulary = genes
• Grammar = rules about the arrangement of information
• Literature = the instructions to make a human
• Alphabet = four bases of DNA
• Word = codon (three ‘letter’ code for an amino acid)
Watson, Crick, Franklin and Wilkins elucidated the biochemical structure of DNA in 1953. Their description of the helical structure revealed how the molecule was able to replicate itself and thus explained the cellular mechanism of reproduction. DNA is composed of two strands of sugar phosphate molecules that are joined together to form long chains (Fig. 7.1). The strands of DNA are made up of repeating units called nucleotides. The DNA nucleotide has three components: a deoxyribose sugar, a phosphate group and a base. There are four types of bases: thymine and cytosine, which have single-ring structures, and adenine and guanine, which have double-ring structures. DNA exists as a double-stranded molecule wound into a helix. The strands are kept together by hydrogen bonding between the bases. The bases are of different sizes and have a different potential number of hydrogen bonds so they always pair in the same ways. Adenine (A) and thymine (T) pair with two hydrogen bonds: cytosine (C) and guanine (G) pair with three. This means that the sequence of the bases is complementary; the sequence of bases on one strand can be deduced from the sequence on the other strand.
The arrangement of base pairs of the two strands is like the rungs of a ladder or teeth of a zip. When DNA replicates, the strands unwind and the hydrogen bonds holding the base pairs together separate (unzip). Each strand acts as a template for the synthesis of another new strand of complementary DNA bases to form from nucleotides that enter the nucleus through the nuclear pores (Fig. 7.2). So two new DNA double helices are formed, each with one strand of ‘old’ DNA and a newly synthesized strand. Thus the replication is described as semiconservative. Replication occurs as part of mitosis or cell division. Replication of DNA means that the chromosomes have double their nuclear material in preparation for dividing into two separate cells. Therefore, the chromosome is formed of two identical chromatids.
(Reproduced with permission from Brooker, 1998).
The replication of the entire human genome is achieved through the process of mitosis, which is part of the cell cycle (Fig. 7.3). Cellular replication results in growth of tissues through hyperplasia (an increase in the number of cells); each cell has the identical genetic message (DNA content) to its parent cell. Mitotic rates are different for different types of cells. Cells that divide rapidly (have a high mitotic index) include skin and gut epithelial cells, spermatogonia and tumour cells. With increased age the mitotic rate slows down so skin renewal, for instance, takes longer and the appearance of the skin is more aged. Drugs used to treat cancers also inhibit mitosis so their side effects are mostly clearly manifested in normal cells with high mitotic rates, causing problems with nutrient absorption and decreasing male fertility. Many cells, such as brain, heart and liver cells, have an extremely slow rate of mitosis and do not regenerate or heal well after injury. Mitosis is a continuous process but for ease of description is traditionally described in distinct phases: prophase, metaphase, anaphase and telophase (Fig. 7.4). Interphase is the name given to the gap between mitotic divisions.
(Reproduced with permission from Brooker, 1998.)
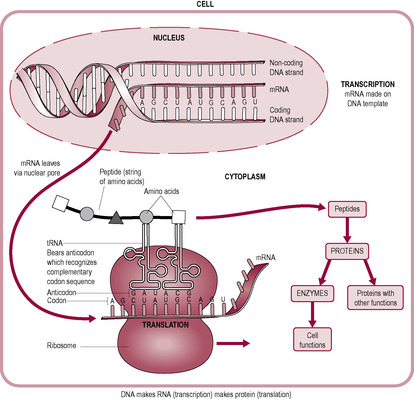
The structure of DNA allows both ease of replication and duplication of the genetic message prior to cell division, and also a method of directing protein synthesis and ultimate cell function. The DNA message is interpreted as a specific protein product. The genes in the DNA strand contain exons, regions that will be translated to proteins, interspersed with introns, regions which are not transcribed into proteins. Proteins are synthesized at the ribosomes of the cell, whereas the encoded information, in the form of DNA, remains within the nucleus. The information is carried from DNA to the site of protein synthesis by the second type of nucleic acid, RNA. Whereas DNA is a double strand, RNA exists as a single strand of sugar phosphate units, and has ribose sugar units (instead of deoxyribose) and similar complementary base molecules to those found in DNA, except that uracil instead of thymine pairs with adenine. RNA also exists as different forms with different functions. Initially a gene is transcribed as nuclear (or ‘premessenger’) RNA (nRNA). nRNA is modified to form mRNA. It is messenger RNA (mRNA) that carries the message from the nucleus to the ribosome, as a complementary strand of mRNA is formed using a stretch of unwound DNA as a template. mRNA is shorter than nRNA because nRNA contains the introns that are spliced out (removed) as the nRNA moves from the nucleus where it is formed to the cytoplasm where it is translated to form an amino acid chain that will form the protein. Splicing allows genes to form different proteins because the exons can be spliced in different patterns with each pattern generating a specific protein. The process of splicing is carried out by small nuclear RNAs (smRNA) called spliceosomes. The process where one gene can code for multiple proteins (‘splice variants’) means that there are about three times as many possible proteins as there are genes which is why the human genome project identified far fewer genes than was originally anticipated.
The DNA contains genes but only specific genes will be expressed in any particular cell at any particular time. Gene expression describes the means by which information from a gene drives the synthesis of a functional gene product which is usually a protein. Molecular biology techniques have allowed in-depth investigation of the function of single genes. There are several ways in which gene expression can be regulated. These include controlling which particular genes are transcribed, selective processing of the transcribed DNA to control which RNA become cytoplasmic mRNA, selective translation of mRNA and post-translational modification of the proteins produced from mRNA (Sadler, 2010).
The process starts with the DNA strands separating like a zip pulling open in the middle. This is the reverse process to the way it coils when condensing into chromosomes (Fig. 7.5). Only one strand of DNA, the coding or ‘sense’ strand, is used as the template; the other is described as non-coding or ‘non-sense’. The mRNA chain is built by RNA polymerase enzymes as the bases pair with the DNA template. This is called transcription (Fig. 7.6).
(Adapted with permission from Goodwin, 1997.)
The whole gene is transcribed but not all of it is used so the primary transcription product mRNA is modified (cut and spliced) into functional mRNA (Fig. 7.7). The parts of the mRNA that are removed have been copied from parts of the gene called introns and those that are retained come from the parts of the DNA known as exons. It is estimated that only about 2–5% of the total genome (genetic code or DNA) is composed of exons and actually codes for protein synthesis. Some of the DNA modulates genetic expression, switching the process of protein synthesis on and off; these control genes are referred to as operator, regulator and inducer genes. Introns form the majority of the DNA sequence and do not appear to be involved in coding for protein synthesis, although they may allow different proteins to be formed from the same length of DNA. Much of the genome (about 98%) may be composed of redundant genes that are no longer activated and involved in the synthesis of proteins. These unused stretches of DNA are used to compare tissue samples for DNA fingerprinting.
(Reproduced with permission from Goodwin, 1997.)
Single nucleotide polymorphisms or SNPs (pronounced snips) are DNA sequence variations that occur when a single nucleotide in the genome is altered, often with the substitution of cytosine with thymine. Variations that occur in at least 1% of the population are considered to be SNPs. There are more than 1.4 million SNPs in the human genome, occurring approximately every 100–300 bases and accounting for up to 90% of all human genetic variation. These variations in the human genome alter how individuals respond to disease, infection, drugs and so on. SNPs are valuable because they do not change much from generation to generation and can be targeted for biomedical research and developing drugs.
The term ‘genome’ refers to a complete DNA sequence of one set of chromosomes of an organism. As such, it does not describe the genetic polymorphism (diversity) of a species. To understand how variations in DNA cause particular traits or diseases will require comparison between individual genomes. The Human Genome Project (HGP) was established as a multinational cooperative research project in 1990 to map the common human nucleotide sequence of more than 3 billion DNA bases in some reference human genomes (the DNA of a few anonymous donors). It was hoped that identification of the 20000–25000 genes in the human genome would accelerate progress to diagnosing, treating and ultimately preventing diseases as well as answer questions about evolution. As individuals (except for identical twins) have unique genomes, the project involved determining the sequence of many versions of each gene. In April 2003, it was announced that 99% of the genome had been sequenced and in May 2006 the sequence of the final chromosome was published. There are still a few DNA sequences to be resolved including the repetitive central regions close to the centromeres and the telomeres, the repetitive terminals of the chromosomes which become progressively shorter with age. The mapping of the genome allows a framework for looking at differences in DNA sequences in individuals so variations in DNA sequence associated with diseases could be identified. The HGP has been supported by remarkable technological progress in bioinformatics, statistics and biotechnology. The HGP raises some complex ethical, legal and social implications such as gene patenting
When transcription and post-transcription modification are complete, the finished functional mRNA strand detaches from the DNA and leaves the nucleus, via a nuclear pore, to go to the ribosomes. Ribosomes are structures formed of two subunits made of protein and another type of RNA, ribosomal RNA (rRNA). mRNA attaches to ribosomes and the sequence of bases of the mRNA is decoded to direct the synthesis of a protein. This step is called translation (Fig. 7.8). The mRNA sequence is ‘read’ three bases at a time. A particular sequence of three bases is called a codon; each codon prescribes that a specific amino acid is incorporated into the final amino acid chain of the overall protein structure. There are 20 amino acids; however, as a three-base genetic code allows the potential of 4 × 4 × 4 = 64 permutations, most amino acids are coded for by more than one codon (Fig. 7.9).
(Reproduced with permission from the Open University, 1988.)
Another form of RNA in the cytoplasm, called transfer RNA (tRNA), carries amino acids to the ribosome to be incorporated into the protein chain. There are different types of tRNA, each one with a specific binding site for a particular amino acid at one end and an ‘anticodon’, which recognizes the codon on the mRNA at the other end. The first amino acid of a new protein is methionine. The next amino acid joins to the carboxyl group of methionine with a peptide bond. Successive amino acids join, forming a chain of amino acids until a ‘stop’ codon on mRNA signals the end of the chain. The sequence of amino acids determines the primary structure of the protein. The further configuration of the protein is determined by the interactions between different amino acids on the chain, which change the protein shape into a ‘folded’ structure, the final shape determining its function. Hence the sequence of bases of the gene, or region of DNA, determines the sequence of amino acids, which in turn prescribes the structure and function of the protein.
The copying of DNA has to be accurate. If mistakes are introduced into a region of DNA that is expressed as a protein (i.e. into an exon), the altered sequence of amino acids can change the structure of the protein. This permanent and transmissible change in base sequence of DNA is described as a mutation. Mutations can lead to death of a cell or cause cancer. They are considered to be the driving force of evolution; favourable mutations tend to accumulate and less favourable ones tend to be removed by natural selection. It is estimated that mutations occur every half an hour in each person but a mutation in a functional gene only occurs once in five generations. A mutation can be described as ‘descent with modification’. DNA has regions of ‘hotspots’ where the mutation rate can be up to 100 times more frequent than normal. New gene mutations are associated with increasing paternal age (above 35 years); it is suggested that new gene mutations are exclusively inherited from the father and occur during spermatogenesis. All dominant mutations seem to arise in the male germline and may be caused by fragmentation induced by free radical damage (Aitken and Graves 2002). In mitosis, there are accumulated errors in copying the genetic message. Each chromosome has a specialized length of DNA at its end, which gets shorter with each successive division. About four bases seem to be lost with each successive cell division.
A base pair may be spontaneously replaced by a different base pair (a ‘point mutation’) thus altering the codon and ultimately the amino acid sequence. Age, environmental pressure, radiation and chemicals increase mutation rate. One notable example is haemophilia, the sex-linked genetic condition that afflicted male members of the European Royal Family for several generations. The spontaneous mutation for changed haemoglobin structure may have occurred in one of the gametes forming the zygote that became Queen Victoria. This type of mutation is referred to as a substitution. Mutations may arise as an insertion or deletion of a nucleotide into or from the DNA strand; these mutations could cause a shift in the ‘reading frame’ of the codons or alter splicing of mRNA thus altering the gene product. Mutations may also occur by the complete insertion of new codons or by the deletion of a complete codon, thus altering protein structure by introducing or deleting amino acids in the protein. This can be complicated if codons are duplicated and repeated one after the other, for example in fragile X syndrome.
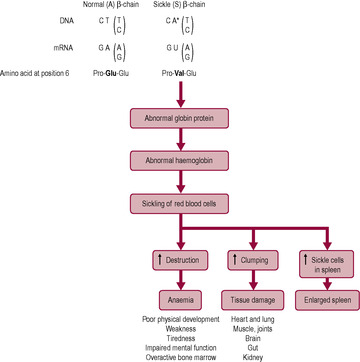
Many mutations occur in the non-coding areas of DNA, so protein structure and function are not affected by the change; these mutations are described as ‘silent’ as they have no effect. If the mutation results in a different codon that codes for the same amino acid as the original, there will also be no effect. However, a different base, or a missing base, will cause a change in the final sequence of amino acids of the protein, which may have serious effects on protein structure and function. An example is sickle cell anaemia (Box 7.3 and Fig. 7.10).
Box 7.3
Most haemoglobin (Hb) in adults is HbA, which has two α-peptide chains and two β-peptide chains forming the haemoglobin molecule. Sickle cell anaemia is an example of a single point mutation where the substitution of one base changes the codon and results in the substitution of one amino acid (Fig. 7.10). Uracil replaces adenine so, instead of glutamic acid, valine is inserted in the protein chain at position 6. Valine has a different charge to glutamic acid so the protein folds differently. The result is that the protein structure of the β-chain of haemoglobin is changed, which affects the molecular shape and oxygen-binding properties. The red blood cells distort into a characteristic sickle shape, particularly at low oxygen tension. Sickle cell anaemia is inherited as an autosomal recessive condition; affected patients have two mutant haemoglobin S genes, one from each parent. The parents are heterozygotes (HbA/HbS) and are thus clinically normal but carry the sickle cell gene. Homozygotes (HbS/HbS) have chronic haemolytic anaemia and are prone to infarction; lifespan is shortened.
The basic characteristics of meiosis – two cell divisions without intervening DNA replication, halving the chromosome complement of the resulting cells – are conserved in evolution. Each species has a characteristic number of chromosomes; humans have 46 chromosomes, arranged as 23 pairs. One chromosome of each pair is maternally derived (from the ovum); the other is paternally derived (from the sperm). (The members of each pair are called homologous; see below.) Human gametes contain only 23 chromosomes, that is half the normal number of chromosomes in other human cells. This reduction from the diploid number of chromosomes (46) to the haploid number (23) is accomplished by meiosis. Meiosis is the process whereby a diploid parent cell produces four haploid daughter cells, resulting in gametes, or sex cells, that are not identical to their parent cells. These gametes are haploid and during meiosis the genetic instructions are randomly assorted, thus generating unique combinations. Meiosis is also described as ‘reduction division’ because the number of chromosomes is reduced from 46 (i.e. 23 pairs) to 23. It occurs in two successive divisions (meiosis I and II), each of which can be divided into steps (Fig. 7.11). Meiosis II is very similar to mitosis.
(Reproduced with permission from Goodwin, 1997.)
In anaphase I, there is random segregation of each member of the chromosome pairs with a maternal and a paternal chromosome randomly going to a particular end of the cell. This would theoretically generate 223 (i.e. 8,388,608) different possibilities of gamete combination. However, the crossing over of genetic material between the chromosomes adds far more variation. Meiosis allows the genomes of the parents to be combined to form an individual whose genome is related to their parents and siblings but is unique.
Mammalian oogenesis begins meiotic development during fetal development but arrests in meiosis I and does not complete meiosis I until ovulation; the second division is only completed if the egg is fertilized. Oogenesis, therefore, requires several stop and start signals and, in humans, may last for several decades. The longer an oocyte is immobilized at prophase I, the greater is the chance of failure of separation of the homologous chromosomes (non-disjunction). Often genetic abnormalities arise as extra genetic material is incorporated into the genome. If an extra chromosome is inserted, the condition is referred to as trisomic (Table 7.1). Most combinations of trisomy are not seen, but there is no reason to believe that certain chromosomes are more susceptible to failed disjunction. Those seen are probably those that are compatible with fetal survival, although they may cause congenital abnormalities or affect neonatal survival. Sometimes extra chromosomal material may become attached to a chromosome, making it abnormally long. Rarely, a condition called triploidy occurs where the chromosomes of the zygote are in triplicate rather than the normal duplicate complement. This condition is not compatible with embryo survival but is sometimes found in products of a failed conception (early miscarriage) and is associated with a high incidence of hydatidiform mole (see Chapter 6). Imperfect disjunction also causes conditions where the genome is lacking part or a whole chromosome. For example, there is only one X chromosome present in Turner’s syndrome (see Chapter 5) and Wolf–Hirschhorn syndrome is caused by loss of chromosomal tissue from chromosomes 4 and 5.
Each gene has a specific location on a specific chromosome, which is referred to as a locus (plural: loci). Each chromosome may have 1000–2000 different genes, each with its own location and function. The visualization of the chromosomes from a cell is described as a karyotype (Box 7.4) (Case study 7.1). Of the 23 pairs of chromosomes that constitute the human genome, 22 pairs of chromosomes can be seen in both sexes; these are referred to as the autosomes and contain the autosomal genes. The 23rd pair of chromosomes comprises the sex chromosomes; these are homologous within the female (i.e. XX) but in the male the XY arrangement consists of a pair of non-homologous chromosomes.
Box 7.4
Karyotyping is the method of visualizing the chromosomes in an ordered display of the chromosomes as they appear in the nucleus of a cell during metaphase of mitosis. For a fetal karyotype, a sample of amniotic fluid is removed. The cells are centrifuged to concentrate the fetal cells. The supernatant can also be used diagnostically for biochemical tests such as investigation of enzyme deficiencies, protein defects and gene alterations. Alternatively, cells may be taken from the chorionic villus. A karyotype of adult cells is usually derived from a sample of venous blood, where the anuclear red blood cells are lysed and the washed remaining cells are, therefore, white blood cells containing nuclei.
The fetal cells or white blood cells are grown in cell culture. The time taken for this depends on the number of cells in the original sample. Contamination of the sample can interfere with the success of the method. Colchicine, a chemical poison, is added to the culture medium to prevent spindle formation. Thus, mitosis in all cells is halted at the metaphase stage when the chromosomes are maximally contracted and well defined as paired chromatids (therefore they take on the typical X-shaped appearance). The cells, all halted at the same stage, can be separated from the culture medium. Exposure of the cells to hypotonic saline causes the nucleus to swell so the chromosomes are spread out. The cells are then fixed and stained. Visualization of the karyotype is done by computer-aided photographic techniques. The chromosomes are ordered according to size with the homologous autosomes being paired together. The chromosomes of pair number 1 are the longest and those of pair number 22 are the shortest. The position of the centromere is also used to sort the chromosomes into order. Stains that bind preferentially to some areas of the chromosome, producing a distinct pattern of bands, can be used to identify the chromosomes. Karyotypes can be used to identify gross abnormalities such as additional or missing chromosomes and missing or duplicated parts of chromosomes. However, a normal karyotype does not reveal the presence of abnormal genes at specific loci. In order to identify such genes, the chromosomes are stained, which produce a pattern or banding enabling an abnormal gene or a marker gene to be identified. A marker gene is a gene that is often found in close proximity to an abnormal gene; the closer the marker gene to the abnormal gene, the higher is the association.
Occasionally, results from karyotyping may be complicated by mosaicism. Mosaicism, a different number of chromosomes in different populations of cells may occur for instance where the chorionic tissue has a different number of chromosomes to the fetus.
Surya presents herself to a midwife at 8 weeks’ gestation demanding that she needs to know the sex of her baby because if it was a female infant she would rather have a termination than proceed with the pregnancy. What should the midwife do in this situation? Are there any circumstances when fetal sex determination is justified?
The sex chromosomes provide the mechanism for the determination of sex and the differentiation into male morphology, which is usually dependent on the inheritance of a Y chromosome (see Chapter 5). As well as sex determination and identity, other genetic traits can be inherited on the sex chromosomes (see below).
It is thought that the sex chromosomes originated from a pair of autosomes (see Chapter 7) during the evolution of sex determination (Graves, 2002). The X and Y chromosomes are very different in size and sequence compared to the other 22 pairs of autosomes. The Y chromosome is very small in comparison to the X chromosome and is completely different from the X chromosomes except at its tips. These identical regions at the tips, known as the pseudoautosomal regions, contain most of the Y chromosome genes involved in control of growth and allow the pairing of the X and Y chromosome and crossing over during cell division. The X chromosome is about 5% of the total length of a single set of chromosome and bears about 3000–4000 genes, many of which are conserved (identical to those of other placental mammals). The Y chromosome contains only about 45–50 genes, many of which appear to be non-functional; others are involved with male differentiation and spermatogenesis, implantation and promoting placental growth. It is suggested that the Y chromosome is particularly vulnerable to mutations and gene deletions because it cannot retrieve lost genetic information by homologous recombination and that, over the past 300 million years, it has already lost most of its original 1500 genes and continues to deteriorate; at its present rate of decay (losing about five genes per million years), it will self-destruct in about 10 million years (Aitken and Graves, 2002). This has already happened in the mole vole, which has lost the Y chromosome and all of its genes from the genome. An alternative view is that the Y chromosome, rather than being ‘damaged’, is an efficient carrier of male-specific genes, rationalized by evolutionary selection (Craig et al., 2004); there has not been any genes lost from the Y chromosome since the ancestral paths of humans and chimpanzees diverged (Goto et al., 2009).
Each pair of autosomes is homologous; this means that their gene arrangements, although not necessarily the specific gene at each locus, are identical. So although the genes at a specific locus code for a specific physiological feature these features in themselves may vary. For instance, the genes at a particular locus may code for eye colour, but this could be blue eye colour on the chromosome inherited from one parent and brown eye colour on the chromosome inherited from the other parent. Genes that code for the same physical feature but produce variations in that feature are called alleles.
If the genes are identical alleles, then the structure and coding of the pair are referred to as being homozygous. If the genes are differing alleles then the pair is referred to as being heterozygous. If one copy of a gene is required for a trait to be expressed (i.e. for the feature to be ‘visible’ in the resultant individual), the gene is described as being dominant. If two copies are required, the gene is described as being recessive. Autosomal traits (genetic instructions carried on the autosomes) can be expressed as either dominant or recessive traits. Simple inheritance of these traits can be predicted diagrammatically (see Figs. 7.12 and 7.16).
Get Clinical Tree app for offline access
