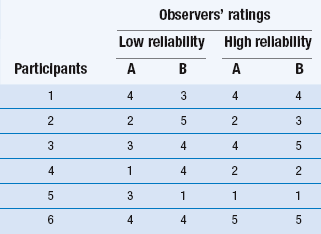
14 The process of converting theoretical ideas to a precise statement of how variables are to be measured is called operationalization. It is important that researchers give exact details of how the measurements were taken in order that others may judge their adequacy and appropriateness and be in a position to repeat the procedures in a new study. Data collection is a very important stage of the research process. A quantitative study that is adequate in terms of design, sampling methods and sample size may nevertheless have limited value due to the use of inadequate measurement techniques. Let us now discuss operationalization. A distinction is commonly drawn between objective and subjective measures, often with overtones of suspicion of poor quality directed towards so-called ‘subjective’ measures. Let us make a much less value-laden distinction and define them as follows: objective measurements involve the measurement of physical quantities and qualities using measurement equipment; subjective measures involve ratings or judgements by humans of quantities and qualities. In general, subjective measures are observations (see Ch. 13) of values measured on nominal or ordinal scales, while objective measures are used to produce scores on interval or ratio scales. We will discuss levels of measurement at the end of this chapter. Before these specific test properties are reviewed, it is useful to review some basic concepts in test theory. In any measurement, we have three related concepts: the observed value or test score, the true value or test score and measurement error. Thus if I could be weighed on a completely accurate set of weighing scales, my true score might be 110 kg. However, the scales that I use in my bathroom might give me a reading of 100 kg. The difference between the observed score and my true score is the measurement error. This relationship can be expressed in the form of an equation such that: Table 14.1 illustrates examples of both high and low inter-observer reliability on ratings of patients on a five-point scale. Let’s imagine that this scale measures the level of patient dependency and need for nursing support. As we mentioned earlier, the degree of reliability is quantitatively expressed by correlation coefficients. However, by inspection you can see that in Table 14.1 there is a high degree of disagreement in the two observers’ ratings in the ‘Low reliability’ column. In this instance the clinical ratings would be unreliable, and inappropriate to use in the research project. However, the outcome shown in the ‘High reliability’ column in Table 14.1 shows a high level of agreement.
Measurement
Operational definitions and measurement
Objective and subjective measures
Desirable properties of measurement tools and procedures
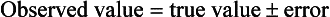
Reliability
Inter-observer (inter-rater) reliability
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Measurement
Get Clinical Tree app for offline access
