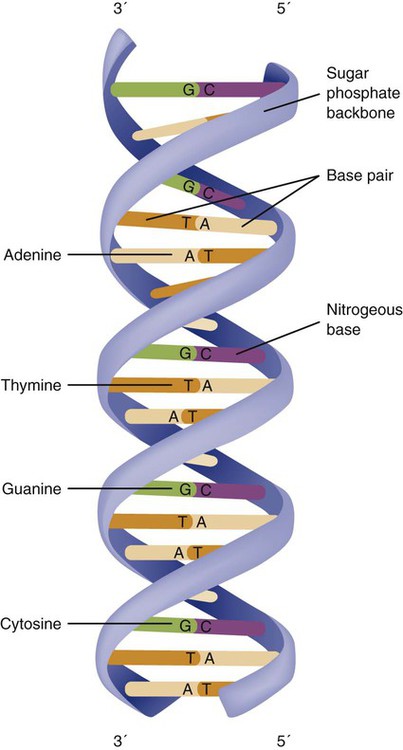
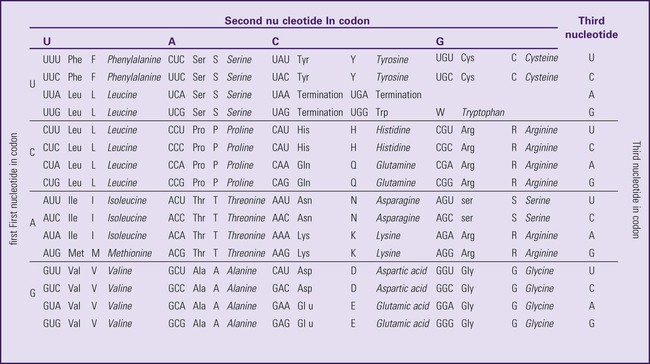
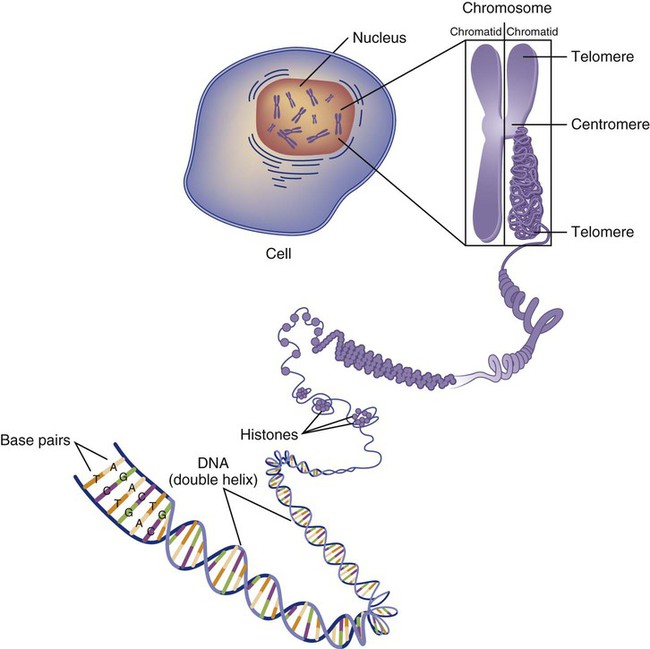
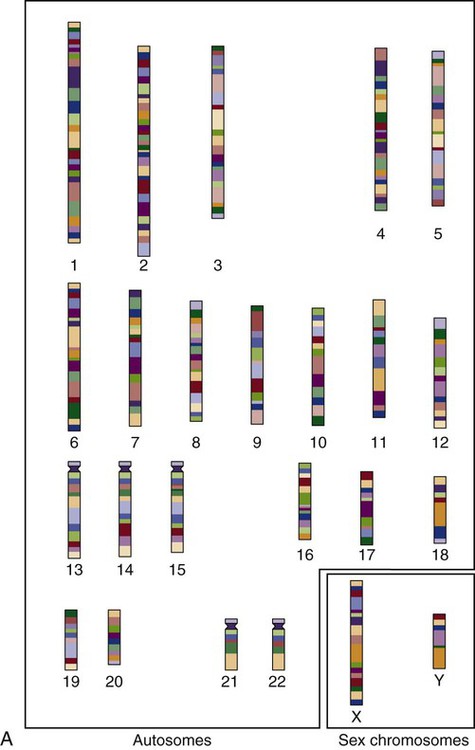
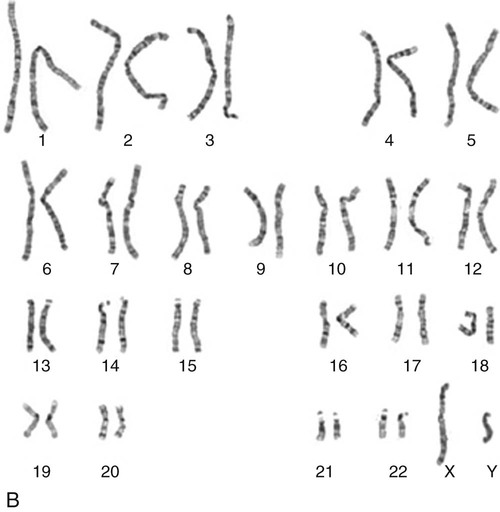
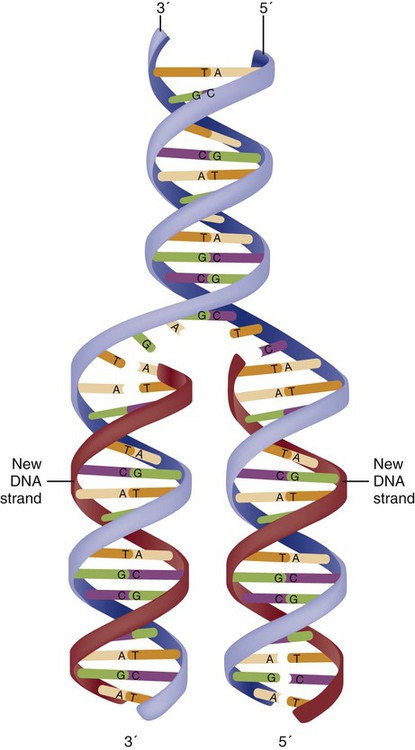
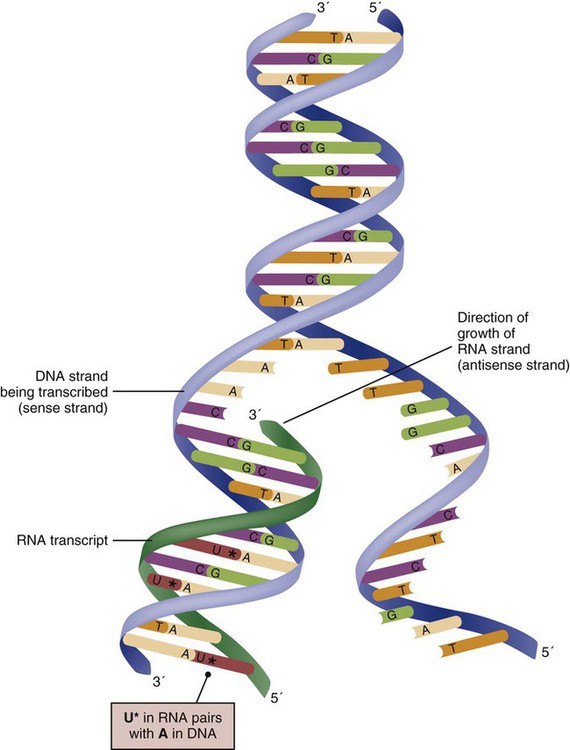
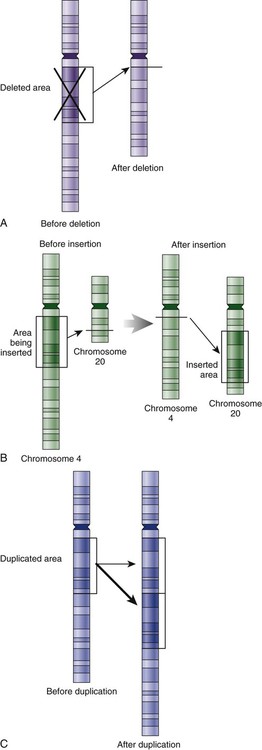
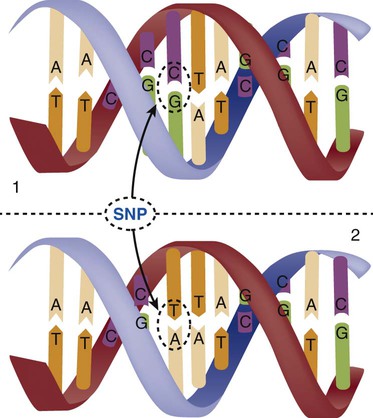
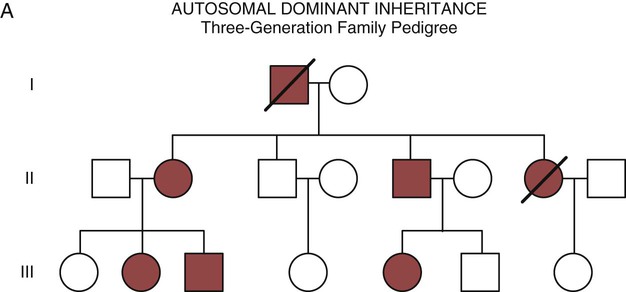
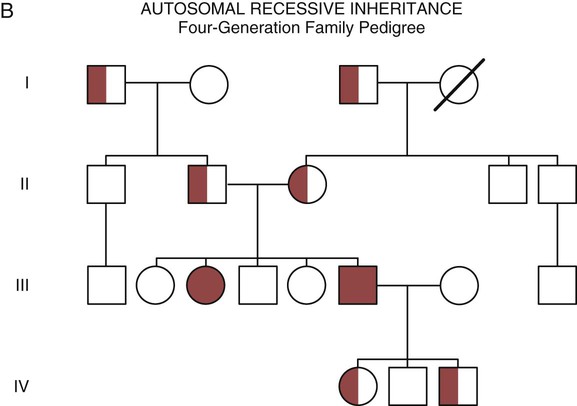
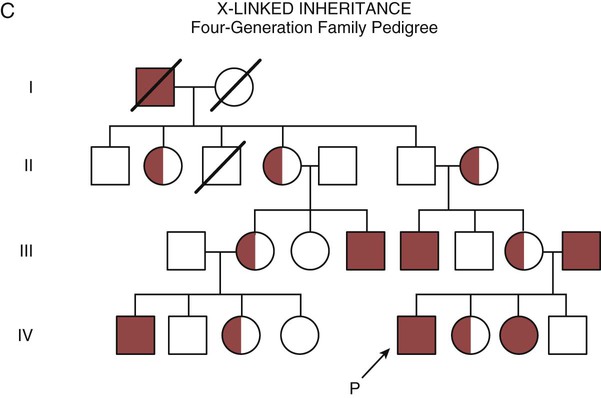
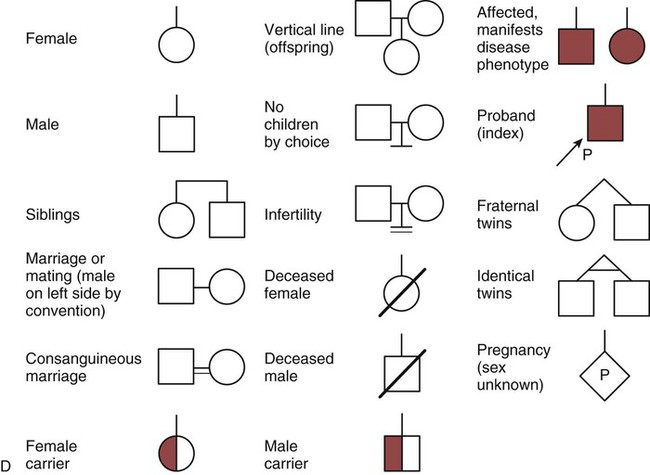
The field of genetics and genomics continues to expand and affect crucial aspects of health care. Genetic testing does not yet have a large role in the critical care unit, but given the exponential growth of knowledge in this field, and the decreasing costs of genomic sequencing, the day when personalized health care will include a genetic screen to tailor treatment to individual biology is on the horizon.1 This chapter includes an overview of the biologic basis of genomics, a description of the different types of genetic and genomic studies, and the growing impact of pharmacogenetics. It also incorporates some examples of genetic diseases and pharmacogenetic syndromes in critical care. A list of genetic and genomic terms is provided at the end of the chapter. Genetics is the study of heredity, particularly as it relates to the ability of individual genes to transfer heritable physical characteristics. Genes are specific sequences of deoxyribonucleic acid (DNA) located on chromosomes within the nucleus of each cell (Fig. 4-1). Genes contain the blueprint for protein production that results in the physical characteristics of each individual. The pioneering work in human genetics has focused on single-gene variants that are rare in the population but have a large effect for the affected individual and follow classic inheritance patterns. About 6,000 rare disorders have been identified, and while single-gene conditions are relatively rare in the population, cumulatively they affect about 25 million people.1,2 Single-gene disorders include Huntington’s disease, Tourette syndrome, cystic fibrosis, and Duchenne muscular dystrophy.2 In single-gene variant disorders the influence of genetics is strong and the environmental effect is very weak. Genomics refers to the study of all of the genetic material within the cell and encompasses the environmental interaction and impact on biologic and physical characteristics. Thus, genomics is a much larger and more complex area of study. The genome is the complete set of DNA in an organism. Each human nucleated somatic cell contains a copy of the complete genome. The exceptions are reproductive cells (oocytes and sperm), which contain only one half of the paired chromosomes, and red blood cells, because they do not have a nucleus. The human genome contains between 20,000 and 25,000 protein-coding genes, which represent less than 2% of the total genome.3 Many disease conditions that are commonly seen in the modern world result from a confluence of both environmental and genomic influences. These are described as complex traits or polygenic conditions.4 Furthermore, environmental conditions can alter the expression of different genes and consequently enhance the signs and symptoms associated with a disease. This represents a relatively new field of research known as epigenetics.5 Coronary artery disease is an example of a widespread disease that has both a strong environmental component (diet, obesity, diabetes, smoking) and a genomic effect that alters risk of developing the condition.4 Whole genome sequencing methods and genome wide association studies (GWAS) are employed to examine multiple genes simultaneously. As the cost of genomic sequencing plummets, this will increasingly become a viable clinical option.6 Nowhere is the genomic influence more evident than in pharmacogenomics, or the unique individual response to medications (environmental impact) based upon gene expression (genomic impact).7 The nucleus inside each human cell contains each person’s full genetic blueprint of 23 pairs of chromosomes—22 pairs of autosomes and 1 pair of sex chromosomes—making the total 46. A number system is used to identify each chromosome. The chromosomes are traditionally arranged in order of size, starting with the largest (chromosome 1) to the smallest (chromosome 22), with the sex chromosomes placed last or to the side. A schematic of this chromosome arrangement to show the variation in size is shown in Figure 4-2A; the chromosomes are obviously not arranged this way inside the cell. A karyotype is the arrangement of human chromosomes from largest to smallest, as shown in the sequence in Figure 4-2B. Each chromosome consists of an unbroken strand of DNA. To fit all of this genetic material inside the cell nucleus, the DNA is tightly coiled inside the chromosomes in a hierarchical order of compact structures. A specialized class of proteins called histones organizes the double-stranded DNA into what looks like a tightly coiled telephone cord (see Fig. 4-1). Each somatic chromosome, also called an autosome, is made of two strands, called chromatids, which are joined near the center (see Fig. 4-1). This central region is called the centromere, and the ends of the chromatids are called telomeres. The segments of the chromosome separated by the centromere are called arms. The shorter arm of each chromosome is called p (for petit, or small), and the longer arm is called q. Differential staining of chromosomes produces alternating dark and light transverse bands. The bands are labeled p1, p2, p3, and so forth on the p arm and q1, q2, q3, and so forth on the q arm, counted from the centromere toward the telomeres. The subunits within each DNA strand are called nucleotides or bases, and they are combined in pairs to form the rungs of the DNA ladder. Four nucleotide bases—adenine (A), thymine (T), guanine (G), and cytosine (C)—comprise the “letters” in the genetic DNA “alphabet.” Each nucleotide base is attached to a phosphorylated molecule of the 5-carbon sugar deoxyribose that forms the backbone of the DNA chain and can be visualized as the two sides of a ladder that have been twisted around (Fig. 4-3). The bases in the double helix are paired T with A, and G with C. The nucleotide bases are designed so that only G can pair with C and only T can pair with A to achieve a consistent distance across the width of the DNA strand. The TA and GC combinations are known as base pairs (see Fig. 4-3). There are approximately three billion bases in the human genome, based on findings from the Human Genome Project.3 The two DNA strands are orientated in opposite directions. Each DNA strand has a specific direction that is labeled as the 3′ end or the 5′ end (pronounced 3 prime, and 5 prime) (see Fig. 4-3). Because the DNA strands face in opposite directions, the 3′ end of one strand is always matched to the 5′ end of the other strand. This fact becomes important for replication (discussed next). The 3′ end is described as the leading strand because new nucleotides can be added only at the 3′ end. Before a cell divides, it needs to make a second copy of the entire DNA content within the cell. This process is called DNA replication. Sections of the DNA double helix separate longitudinally, creating openings between base pairs, known as replication bubbles, and mirror-image copies are made from the original strands. Stated another way, the original DNA strands provide a template that will be copied. The original is called the parent strands and the mirror-image copies are described as the daughter strands. In Figure 4-4 the parent strand is illustrated by the color blue with the 5′ and 3′ ends of each parent strand labeled. The daughter strands are colored in red. The replication process is facilitated by DNA polymerase, an enzyme that lengthens the DNA strand by the addition of new nucleotide bases at the 3′ end of the daughter strand (Fig. 4-4). After DNA replication is accomplished, the cell uses a sophisticated mechanism for identifying and fixing errors in the replicated strand.8 After this procedure, the cell is ready to divide, and each new cell will contain a copy of the original DNA code. The nucleotides A, T, C, and G can be thought of as “letters” of a genetic alphabet that are combined into three-letter “words” that are transcribed (written) by the intermediary of ribonucleic acid (RNA). The RNA translates the three-letter words into the amino acids used to make the polypeptide chains that constitute proteins. This process may be written as DNA → RNA → protein.9 The process of making an RNA strand from a DNA strand is known as transcription. The strand with the genetic code that is to be transcribed is labeled as the sense strand or sometimes as the coding strand. The other strand, which is the RNA mirror image, is called the antisense or non-coding strand (Fig. 4-5). The reason there are two strands oriented in opposite directions is to facilitate replication of a DNA strand during cell division (see Fig. 4-4), or when proteins are needed (see Fig. 4-5) without compromising the original genetic material. To visualize how the process of transcription works, it may be helpful to study Figure 4-5 and locate the names of the different strands; the DNA strand is colored blue, the RNA strand is colored green to make the distinction clear. Transcription occurs under the guidance of the enzyme RNA polymerase, sections of the DNA double helix unfold and separate into two single strands within the length of the double helix (see Fig. 4-5). The mirror-image DNA strand (shown in red in Fig. 4-4) serves as a template for the synthesis of a complementary, mirror-image strand of RNA (shown in green in Fig. 4-5). The purpose of transcription is to have the RNA mirror strand replicate the genetic code in the original DNA sense strand. When RNA transcribes DNA nucleotides, one significant change occurs. The adenosine (A) DNA base is paired with a uracil (U) base in the RNA transcript (see Fig. 4-5). Each RNA strand also has a 3′ end (can be conceptualized as a head) and a 5′ end (conceptualized as a tail), and the growing RNA strand adds bases only at the 3′ leading end. The RNA strand, called messenger RNA, then leaves the nucleus of the cell, and the next action takes place in the cytoplasm. The next step is to translate the RNA bases into three-letter words (e.g., AUC, UGA) called codons that can be used to specify an amino acid. The 3-base RNA codons are designed to code for one of 20 amino acids. Some codons signal to stop the sequence; these termination sequences are UAA, UAG, and UGA. The three-letter codons are not unique; for example, both UAU and UUC code for the amino acid phenylalanine. Most amino acids can be made from more than one codon. This can be appreciated by an examination of the list of three-letter codons, the corresponding three-letter amino acid abbreviation, the single-letter abbreviation, and the name of the amino acid in Table 4-1. The process by which proteins are made from instructions encoded in DNA is called gene expression. TABLE 4-1 THE GENETIC CODE: AMINO ACIDS* *Amino acids are the building blocks of proteins. The 20 amino acids are constructed from information contained in the DNA blueprint that is translated and transcribed by RNA. This transfer of information from DNA to amino acids is called the genetic code. Triple sets of bases (codons) are transcribed into the 20 amino acids. Sixty-four combinations of codons are possible, and several codons code for the same amino acids. The amino acids are connected in long polypeptide chains that form proteins. Three combinations signal the end of a protein chain: UAA, UAG, and UGA. Each three-letter codon also has a single-letter abbreviation, which is shown in the table. Only a brief review of how DNA contributes to the genetic code is possible in this chapter. The volume of information that underpins genetics and genomics reflects the work of many scientists who performed research to advance this knowledge, and it may take some individual study or additional classes to master the content. An excellent and free online tutorial called “DNA from the Beginning” is available through the Cold Spring Harbor Laboratory website.10 The 41 modules use animation, video interviews, and text to present an interesting and informative introduction to the history and science of genetics.10 Genetic variation is common to all species. It means that individuals do not have the same nucleotides (A, C, T, G) in exactly the same position on the DNA strand. Some nucleotide differences result in the expression of different proteins and physical traits. Many nucleotide changes produce no visible external alteration, although those that have health-related consequences are of great interest to clinicians, patients, and researchers. Genetic variation can result from a variety of changes. It can be a single-letter substitution of one nucleotide base for another that can produce an inappropriate stop codon or produce a codon for a different amino acid. The amino acid codes are shown in Table 4-1. An example of a single-letter switch that results in an increased risk for disease is the G-to-A substitution at nucleotide 1691 in the coagulation factor V gene. This is also an example of a relatively rare single-gene variant that alters the protein product and increases the incidence of deep vein thrombosis (DVT), as described in Box 4-1. Genetic material in the chromosome can also be deleted (Fig. 4-6A), new information from another chromosome can be inserted (Fig. 4-6B), or a tandem repeat (multiple repeats of the same sequence) may produce duplicate genetic material within the chromosome (Fig. 4-6C). Translocation of genetic material describes a process in which chromosomes break and genetic material is moved from one chromosome to another. For example, the Philadelphia Chromosome, or Philadelphia translocation, is a specific chromosomal abnormality associated with chronic myelogenous leukemia (CML). It results from a reciprocal translocation between chromosomes 9 and 22, in which parts of these two chromosomes switch places, producing the oncogenic Philadelphia Chromosome and development of dysregulated tyrosine kinase. CML represents 20% of all adult cases of leukemia.11 When a genetic variant occurs frequently and is present in 1% or more of the population, it is described as a genetic polymorphism. The most common change is the substitution of one single-nucleotide base. A single-letter switch is known as a single-nucleotide polymorphism (SNP), commonly abbreviated and pronounced “snip” (Fig. 4-7). This is significant when the SNP occurs in a region of DNA that codes for an amino acid. If the SNP change alters the amino acid product that is produced, it is called a nonsynonymous SNP, or missense SNP. If a nonsynonymous SNP occurs in a coding region, it may affect protein structure and lead to alterations in phenotype (disease manifestation). An example is the G-to-A coding SNP at the 1691 site of the factor V gene associated with blood coagulation.12 This polymorphism leads to the substitution of an arginine (A) by glutamine (G) at amino acid position 506, which alters one of the cleavage sites for activated protein C. Factor Va inactivation is delayed because the cleavage site is atypical. This change in one amino acid reduces the anticoagulant activity of factor V, creates a hypercoagulable state, and consequently increases the risk for DVT12 (see Box 4-1). Another name for a variant of a gene that occurs at a single locus is an allele. Allele symbols consist of the gene symbol, an asterisk, and the italicized allele designation. For example, the apolipoprotein E gene (APOE) has three major alleles (APOE*E2, APOE*E3, APOE*E4), and each allele codes for a different isoform of the ApoE protein.13 Apolipoprotein E is involved with cholesterol metabolism, and expression of the APOE*E4 allele is associated with the development of hyperlipidemia. APOE*E4 expression also is associated with late-onset Alzheimer’s disease and with a less favorable outcome after traumatic brain injury and brain hemorrhage.13 Not all changes in the DNA sequence have deleterious effects. Most SNPs have no effect because they are synonymous SNPs, variants that code for the same amino acid (see Table 4-1), or because they are located in non-coding genomic region. In some disorders, many genes interact to produce the condition, or there must be an interaction between vulnerable genes and the environment. Cardiovascular atherosclerotic diseases and type 2 diabetes are examples of complex gene disorders that result from an interaction of genetic and environmental factors.4 Pharmacogenetic syndromes are also in this category, resulting from the interactions of genes and medications. Some diseases are caused by alterations in the DNA of the mitochondria, which are intracellular organelles found in the cytoplasm. Mitochondrial DNA is totally different and separate from the double-helix DNA found in the nucleus. Mitochondrial DNA is transferred to offspring by maternal transmission only, because mitochondria occur in oocytes but not in sperm. Most mitochondrial genetic diseases are associated with disorders of enzyme function that disrupts mitochondrial energy production. Tissues and organs that have high energy requirements such as skeletal muscles, the heart, and the central nervous system are most often affected.14 One of the tools used to determine whether a disease has a genetic component is construction of a family pedigree.15 For nurses, it is important to develop the skills to ask questions to elucidate which family members are affected and which are unaffected and then to identify the individuals who may carry the gene in question but do not have symptoms (carriers). Standardized symbols are used in the construction of a pedigree.15 The use of a legend to explain what the symbols mean prevents misinterpretation. The proband is the name given to the first person diagnosed in the family pedigree. Examples of three simple pedigrees that illustrate the single-gene inheritance patterns and the symbols used to construct a pedigree are shown in Figure 4-8 with examples described below. Autosomal dominant inheritance is described as a dominant pattern because only one copy of an affected gene is required to transmit the condition. The person has inherited one affected gene from one parent and one healthy gene from the other parent, and is described as heterozygous for that gene. Typically, the disease appears in every generation. Each child of an affected parent has a 50% chance of inheriting the condition, depending on whether a parent has transmitted the affected gene or not. Male and female offspring are equally likely to inherit and transmit the condition (see Fig. 4-8A). Examples of conditions with autosomal dominant inheritance patterns include familial hypercholesterolemia (FH) and Marfan syndrome. With an autosomal recessive pattern of inheritance, the disease or condition manifests only if the person has received an affected gene from both parents. The parents are carriers of the gene but are not themselves affected. The parents are heterozygous, because they have one copy of a normal gene and one copy of an affected gene. The inheritance pattern for this situation is slightly complex. Any of their children has a 25% chance to inherit in the following combinations: one normal and one affected gene (heterozygous carrier), two normal genes (unaffected), or two affected genes (homozygous affected). Persons who are homozygous for the gene associated with the disease always are affected, which means they demonstrate the phenotype of the disease (see Fig. 4-8B). In autosomal recessive inheritance, the phenotype associated with the condition is seen more often in siblings (sibships) than in the parents. Conditions associated with autosomal recessive inheritance include cystic fibrosis and sickle cell disease. Some diseases are inherited through an X-linked pattern of inheritance. A classic example is the F8 gene, which codes for the protein that makes coagulation factor VIII. The F8 gene is located on the X chromosome.16 Of note, the inheritance of hemophilia B is also sex-linked because the F9 gene, which codes for the protein that makes coagulation factor IX, is also located on the X chromosome.16 In an X-linked disorder, each son has a 50% chance of being hemophiliac, and each daughter has a 50% chance of being a carrier. In a family pedigree, the absence of direct male-to-male transmission makes this condition identifiable as an X-linked disorder. Hemophilia A is an example of a single-gene disorder. Figure 4-8C illustrates an X-linked family pedigree for hemophilia A; a male who is affected (generation I) may pass the X-linked F8 gene only to his daughters (generation II), who may pass the gene to sons who will be affected, or to daughters who will be carriers (generation III). A female will only be affected if she receives a defective X-linked gene from both her father and mother as occurs in generation IV.
Genetics and Genomics in Critical Care
Genetics and Genomics
Genetic and Genomic Structure and Function
Chromosomes
DNA Base Pairs
DNA Replication
DNA Alphabet
Transcription
Translation
Genetic Variation, Mutation and Polymorphism
Variation
Single-Nucleotide Polymorphisms
Alleles
Genetic Inheritance
Genetic Disorders
Complex Gene and Multifactorial Disorders
Mitochondrial Disorders
Genetic History and Family Pedigree
Autosomal Dominant Inheritance
Autosomal Recessive Inheritance
Sex-Linked Inheritance
Hemophilia A and Hemophilia B.
![]()
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


Genetics and Genomics in Critical Care
Get Clinical Tree app for offline access
