CHAPTER 4 Evidence about effects of interventions
After reading this chapter, you should be able to:
As we saw in Chapter 1, clinical decisions are made by integrating information from the best available research evidence with information from our clients, the practice context and our clinical experience. Given that one of the most common information needs in clinical practice relates to questions about the effects of interventions, this chapter will begin by reviewing the role of the study design that is used to test intervention effects before moving on to explaining the process of finding and appraising research evidence about the effects of interventions.
Study designs that can be used for answering questions about the effects of interventions
There are many different study designs that can provide information about the effects of interventions. Some are more convincing than others in terms of the degree of bias that might be in play given the methods used in the study. From Chapter 2, you will recall that bias is any systematic error in collecting and interpreting data. In Chapter 2, we also introduced the concept of hierarchies of evidence. The higher up the hierarchy that a study design is positioned, in the ideal world, the more likely it is that the study design can minimise the impact of bias on the results of the study. That is why randomised controlled trials (sitting second from the top of the hierarchy of evidence for questions about the effects of interventions) are so commonly recommended as the study design that best controls for bias when testing the effectiveness of interventions. Systematic reviews of randomised controlled trials are located above them (at the top of the hierarchy) because they can combine the results of multiple randomised controlled trials. This can potentially provide an even clearer picture about the effectiveness of interventions. Systematic reviews are explained in more detail in Chapter 12.
One of the best methods for limiting bias in studies that test the effects of interventions is to have a control group.1 A control group is a group of participants in the study who should be as similar in as many ways as possible to the intervention group except that they do not receive the intervention being studied. Let us first have a look at studies that do not use control groups and identify some of the problems that can occur.
Studies that do not use control groups
Uncontrolled studies are studies where the researchers describe what happens when participants are provided an intervention, but the intervention is not compared with other interventions. Examples of uncontrolled study designs are case reports, case series and before and after studies. These study designs were explained in Chapter 3. The big problem with uncontrolled studies is that when participants are given an intervention and simply followed for a period of time with no comparison against another group it is impossible to tell how much (if any) of the observed change is due to the effect of the intervention itself. There are some obvious reasons this might occur and these problems need to be kept in mind if you use an uncontrolled study to guide your clinical decision making. Some of the forms of bias that commonly occur in uncontrolled studies are described below.
Controlled studies
Non-randomised controlled studies
You will recall from the hierarchy of evidence about the effects of interventions (in Chapter 3) that case-control and cohort studies are located above uncontrolled study designs. This is because they make use of control groups. Cohort studies follow a cohort that have been exposed to a situation or intervention and have a comparison group of people who have not been exposed to the situation of interest (for example, they have not received any intervention). However, because cohort studies are observational studies, the allocation of participants to the intervention and control groups is not under the control of the researcher. It is not possible to tell if the participants in the intervention and control groups are similar in terms of all the important factors and, therefore, it is unclear to what extent the exposure (that is, the intervention) might be the reason for the outcome rather than some other factor.
We saw in Chapter 2 that a case-control study is one in which participants with a given disease (or health condition) in a given population (or a representative sample) are identified and are compared to a control group of participants who do not have that disease (or health condition). When a case-control study has been used to answer a question about the effect of an intervention, the ‘cases’ are participants who have been exposed to an intervention and the ‘controls’ are participants who have not. As with cohort studies, because this is an observational study design, the researcher cannot control the assembly of the groups under study (that is, which participants go into which group). Although the controls that are assembled may be similar in many ways to the ‘cases’, it is unlikely that they will be similar with respect to both known and unknown confounders. Chapter 2 explained that confounders are factors that can become confused with the factor of interest (in this case, the intervention that is being studied) and obscure the true results.
So not only are control groups essential, but in order to make valid comparisons between groups, they must be as similar as possible at the beginning of a study. This is so we can say with some certainty that any differences that are found between groups at the end of the study are likely to be due to the factor under study (that is, the intervention), rather than because of bias or confounding. To maximise the similarity between groups at the start of a study, researchers need to control for both known and unknown variables that might influence the results. The best way to achieve this is through randomisation.Non-randomised studies are inherently biased in favour of the intervention that is being studied, which can lead researchers to reach the wrong conclusion about the effectiveness of the intervention.2
Randomised controlled trials
The key feature of randomised controlled trials is that the participants are randomly allocated to either an intervention (experimental) group or a control group. The outcome of interest is measured in participants in both groups before (known as pre-test) and then again after the intervention (known as post-test) is provided. Therefore, any changes that appear in the intervention group pre-test to post-test, but not in the control group, can be reasonably attributed to the intervention. Figure 4.1 shows the basic design of a randomised controlled trial.
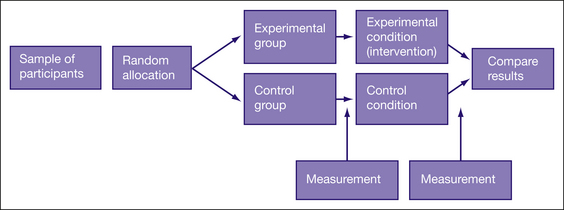
There are a number of variations on the basic randomised controlled trial design, which partly depend on the type or combination of control groups used. There are many variations on what the participants in a control group in a randomised controlled trial actually receive. For example, participants may receive no intervention of any kind (a ‘no intervention’ control), or they may receive a placebo, some form of social control or a comparison intervention. In some randomised controlled trials, there are more than two groups. For example, in one study there might be two intervention groups and one control group or, in another study, there might be an intervention group, a placebo group and a ‘no intervention’ group. Randomised crossover studies are a type of randomised controlled trial in which all participants take part in both intervention and control groups but in random order. For example, in a randomised crossover trial of transdermal fentanyl (a pain medication) and sustained-release oral morphine (another pain medication) for treating chronic non-cancer pain, participants were assigned to one of two intervention groups.3 One group was randomised to four weeks of treatment with sustained release oral morphine followed by transdermal fentanyl for four weeks. The second group received the same treatments but in reverse order. A difficulty with crossover trials is that there needs to be a credible wash-out period. That is, the effects of the intervention provided in the first phase must no longer be evident prior to commencing the second phase. In the example we used here, the effect of oral morphine must be cleared prior to the fentanyl being provided.
How to structure a question about the effect of intervention
In Chapter 2, you learnt how to structure clinical questions using the PICO format: Patient/Problem/Population, Intervention/Issue, Comparison (if relevant) and Outcomes.
In our falls clinical scenario, the population that we are interested in is elderly people who fall. We know from our clinical experience that people who have had falls in the past are at risk of falling again, so it makes sense to target our search for interventions aimed at people who are either ‘at risk’ of falling and/or have a history of falling. The intervention that we are interested in is a falls prevention program. Are we interested in a comparison intervention? While we could compare the effectiveness of one type of intervention with another, for this scenario it is probably more useful to start by firstly thinking about whether the intervention is effective. To do this we would need to compare the intervention to either a placebo (a concept we will discuss later) or to usual care. There are a number of outcomes that we could consider important for people who fall. The most obvious outcome of interest is a reduction in the number of falls. However, we could also look for interventions that consider the factors that contribute to falls such as balance problems or, in this scenario, a person’s confidence (or self-efficacy) to undertake actions that will prevent them from falling.
How to find evidence to answer questions about the effects of intervention
Our clinical scenario question is a question about the effectiveness of an intervention to prevent falls and to improve self-efficacy. You can use the hierarchy of evidence for this type of question as your guide to know which type of study you are looking for and where to start searching. In this case, you are looking for a systematic review of randomised controlled trials. If there is no relevant systematic review, you should next look for a randomised controlled trial. If no relevant randomised controlled trials are available, you would then need to look for the next best available type of research, as indicated by the hierarchy of evidence for this question type that is shown in Chapter 2.
As we saw in Chapter 3, the best source of systematic reviews of randomised controlled trials is the Cochrane Database of Systematic Reviews, so this would be the logical place to start searching. The Cochrane Library also contains the Cochrane Central Register of Controlled Trials which includes a large collection of citations of randomised controlled trials. If you are looking for randomised controlled trials specifically in the rehabilitation field, two other databases that you could consider searching for this topic are PEDro (www.pedro.org.au/) or OTseeker (www.otseeker.com). These databases were explained in Chapter 3. One of their advantages is that they have already evaluated the risk of bias that might be of issue in the randomised controlled trials that they index.
Now that you have found a research article that you are interested in, it is important to critically appraise it. That is, you need to examine the research closely to determine whether and how it might inform your clinical practice. As we saw in Chapter 1, to critically appraise research, there are three main aspects to consider: 1) its internal validity (in particular, the risk of bias); 2) its impact (the size and importance of any
Clinical scenario (continued): Finding evidence to answer your question
You search the Cochrane Database of Systematic Reviews and there are two reviews concerning falls prevention. One of these reviews evaluated the effect of interventions that were designed to reduce the incidence of falls in the elderly, but not just those who are community-living—it also included those in institutional care and hospital care. The other review focussed on population-level interventions. As neither of these reviews is what you are after, you next search OTseeker and find six articles that are possibly relevant. You are specifically interested in interventions aimed at community-dwelling older people and the title of one of these articles matches this. After reading the abstract, you know that this article describes a randomised controlled trial that has investigated the effectiveness of a program (called the ‘Stepping On’ program) for reducing the incidence of falls in the community-living elderly.4 As you found this article indexed in OTseeker, it has been evaluated with respect to risk of bias; however, in order to evaluate whether it also measured self-efficacy as an outcome and to specifically examine the results of the trial and determine whether the findings may be applicable to your clinical scenario, you obtain the full text of the article. You find that it does measure self-efficacy, so you proceed to critically appraise the article. (As most of the trials in OTseeker are pre-appraised, you would normally not need to appraise the risk of bias in the article for yourself. However, as the purpose of this clinical scenario exercise is to demonstrate how to appraise a randomised controlled trial, we will proceed to appraise this article even though it was located in OTseeker.)
Clinical scenario (continued): Structured abstract of our chosen article (the ‘stepping on’ trial)
effect found); and 3) whether or how the evidence might be applicable to your client or clinical practice.
Is this evidence likely to be biased?
In this chapter we will discuss six criteria that are commonly used for appraising the potential risk of bias in a randomised controlled trial. These six criteria are summarised in Box 4.1 and can be found in the Users Guide to the Literature5 and in many appraisal checklists such as the Critical Appraisal Skills Program (CASP) checklist and the PEDro scale.6 A number of studies have demonstrated that estimates of treatment effects may be distorted in trials that do not adequately address these issues.7,8 As you work through each of these criteria when appraising an article, it is important to consider the direction of the bias (that is, is it in favour of the intervention or control group?) as well as its magnitude. As we pointed out in Chapter 1, all research has flaws, but we do not just want to know what the flaws might be, but whether and how they might influence the results of a study.
BOX 4.1 KEY QUESTIONS TO ASK WHEN APPRAISING THE VALIDITY (RISK OF BIAS) IN A RANDOMISED CONTROLLED TRIAL
Was the assignment of participants to groups randomised?
Randomised controlled trials, by definition, randomise participants to either the experimental or control condition. The basic principle of randomisation is that each participant has an equal chance of being assigned to any group, such that any difference between the groups at the beginning of the trial can be assumed to be due to chance. The main benefit of randomisation is related to the idea that this way, both known and unknown participant characteristics should be evenly distributed between the intervention and control groups. Therefore, any differences between groups that are found at the end of the study are likely because of the intervention.9
Random allocation is best done by a random numbers table which can be computer-generated. Sometimes it is done by tossing a coin or ‘pulling a number out of a hat’. Additionally, there are different randomisation designs that can be used and you should be aware of them. Researchers may choose to use some form of restriction, such as blocking or stratification, when allocating participants to groups in order to create a greater balance between the groups at baseline in known characteristics.10 Different randomisation designs are summarised below:
healthcare services among low income, minority mothers.11 Two hundred and eighty-six mother–infant dyads recruited from four different sites in Washington DC were assigned to either the standard social services (control) group or the intervention group. To ensure that there were comparable numbers within each group across the four sites, site-specific block randomisation was used. By using block randomisation, selection bias due to demographic differences across the four sites was avoided.
Was the allocation sequence concealed?
As we have seen, the big benefit of a randomised controlled trial over other study designs is the fact that participants are randomly allocated to the study groups. However, the benefits of randomisation can be undone if the allocation sequence is manipulated or interfered with in any way. As strange as this might seem, a health professional who wants their client to receive the intervention that is being evaluated may swap their client’s group assignment so that their client receives the intervention being studied. Similarly, if the person who recruits participants to a study knows which condition the participants are to be assigned to, this could influence their decision about whether or not to enrol them in the study. This is why assigning participants to study groups using alternation methods, such as every second person who comes into the clinic, or assigning participants by methods such as date of birth is problematic because the randomisation sequence is known to the people involved.9
Knowledge about which group a participant will be allocated to if they are recruited into a study can lead to the selective assignment of participants, and thus introduce bias into the trial. This knowledge can result in manipulation of either the sequence of groups that participants are to be allocated to or the sequence of participants to be enrolled. Either way, this is a problem. This problem can be dealt with by concealing the allocation sequence from the people who are responsible for enrolling clients into a trial or from those who assign participants to groups, until the moment of assignment.12 Allocation can be concealed by having the randomisation sequence administered by someone who is ‘off-site’ or at a location away from where people are being enrolled into the study. Another way to conceal allocation is by having the group allocation placed in sealed opaque envelopes. Opaque envelopes are used so that the group allocation cannot be seen if the envelope is held up to the light! The envelope is not to be opened until the client has been enrolled into the trial (and is therefore now a participant in the study).
Hopefully, the article that you are appraising will clearly state that allocation was concealed, or that it was done by an independent or off-site person or that sealed opaque envelopes were used. Unfortunately though, many studies do not give any indication about whether allocation was concealed,13,14 so you are often left wondering about this, which is frustrating when you are trying to appraise a study. It is possible that some of these studies did use concealed allocation, but you cannot tell this from reading the article.
Were the groups similar at the baseline or start of the trial?
Differences between the groups that are present at baseline after randomisation have occurred due to chance and, therefore, determining if these differences are statistically significant by using p values is not an appropriate way of assessing such differences.15 That is, rather than using the p value that is often reported in studies, it is important to examine these differences by comparing means or proportions visually. The extent to which you might be concerned about a baseline difference between the groups depends on how large a difference it is and whether it is a key prognostic variable, both of which require some clinical judgement. The stronger the relationship between the characteristic and the outcome of interest, the more the differences between groups will weaken the strength of any inference about efficacy.5 For example, consider a study that is investigating the effectiveness of group therapy in improving communication for people who have chronic aphasia following stroke compared with usual care. Typically, such a study would measure and report a wide range of variables at baseline (that is, prior to the intervention) such as participants’ age, gender, education level, place of residence, time since stroke, severity of aphasia, side of stroke and so on. Some of these variables are more likely to influence communication outcomes than others. The key question to consider is: are any differences in key prognostic variables between the groups large enough that they may have influenced the outcome(s)? Hopefully if differences are evident, the researchers will have corrected for this in the data analysis process.
One other area of baseline data that articles should report is the key outcome(s) of the study (that is, the pre-test measurement(s)). Let us consider the example presented earlier of people receiving group communication treatment for aphasia to illustrate why this is important. Although such an article would typically provide information about sociodemographic variables and clinical variables (such as severity of aphasia, type of stroke and side of stroke), having information about participants’ initial (that is, pre-test) scores on the communication outcome measure that the study used would be helpful for considering baseline similarity. This is because, logically, participants’ pre-test scores on a communication measure are likely to be a key prognostic factor for the main outcome of the study, which is communication ability.
Were participants, health professionals and study personnel ‘blind’ to group allocation?
People involved with a trial, whether they be the participants, the treating health professionals or the study personnel, usually have a belief or expectation about what effect the experimental condition will or will not have. This conscious or unconscious expectation can influence their behaviour, which in turn can affect the results of the study. This is particularly problematic if they know which condition (experimental or control) the participant is receiving. Blinding (also known as masking) is a technique that is used to prevent participants, health professionals and study personnel from knowing which group the participant was assigned to so that they will not be influenced by that knowledge.10 In many studies, it is difficult to achieve blinding. Blinding means more than just keeping the name of the intervention hidden. The experimental and control conditions need to be indistinguishable. This is because even if they are not informed about the nature of the experimental or control conditions (which, for ethical reasons, they usually are) when they sign informed consent forms, participants can often work out which group they are in. Whereas pharmaceutical trials can use placebo medication to prevent participants and health professionals from knowing who has received the active intervention, blinding of participants and the health professionals who are providing the intervention is very difficult (and often impossible) in many non-pharmaceutical trials. We will now look a little more closely at why it is important to blind participants, health professionals and study personnel to group allocation.
A participant’s knowledge of their treatment status (that is, if they know whether they are receiving the intervention that is being evaluated or not) may consciously or unconsciously influence their performance during the intervention or their reporting of outcomes. For example, if a participant was keen to receive the intervention that was being studied and they were instead randomised to the control group, they may be disappointed and their feelings about this might be reflected in their outcome assessments, particularly if the outcomes being measured are subjective in nature (for example, pain, quality of life or satisfaction). Conversely, if a participant knows or suspects that they are in the intervention group, they may be more positive about their outcomes (such as exaggerating the level of improvement that they have experienced) when they report them as they wish to be a ‘polite client’ and are grateful for receiving the intervention.16
However, there is a common situation that occurs, particularly in many trials in which non-pharmaceutical interventions are being tested, that makes assessor blinding not possible to achieve. If the participant is aware of their group assignment, then the assessment cannot be considered to be blinded. For example, consider the outcome measure of pain that is assessed using a visual analogue scale. The participant has to complete the assessment themselves due to the subjective nature of the symptom experience. In this situation, the participant is really the assessor and, if the participant is not blind to which study group they are in, then the assessor is also not blind to group allocation. Research articles often state that the outcome assessors were blind to group allocation. Most articles measure more than one outcome and often a combination of objective and subjective outcome measures are used. So, while this statement may be true for objective outcomes, if the article involved outcomes that were assessed by participant self-report and the participants were not blinded, you cannot consider that these subjective outcomes were measured by a blinded assessor.



